
65. 自动编码器原理及构建#
65.1. 介绍#
前面我们学习了 GAN 生成对抗网络。你应该可以发现,如果我们按照监督学习和非监督学习进行分类,GAN 明显是一种非监督学习神经网络,因为我们无需对数据进行标注。本次实验中,即将接触到的自动编码器同样是一种无监督神经网络,实验将带你了解它的原理和作用。
65.2. 知识点#
自动编码器介绍
基础自动编码器
去噪自动编码器
65.3. 自动编码器介绍#
自动编码器(英文:Auto encoder),又称自编码器,它是一种用于非监督学习过程的人工神经网络。自动编码器通常又两部分构成:编码器和解码器。下面,我们通过一张图示来对其进行解释。
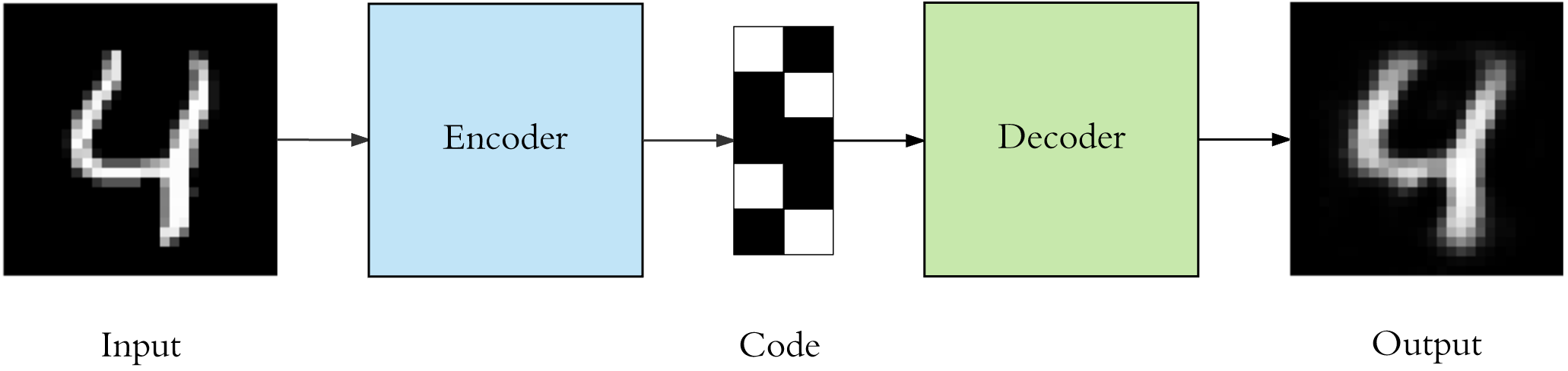
上图展示了一个自动编码器的经典流程:输入经过编码器(Encoder)神经网络编码成 Code,再经过解码器(Decoder)神经网络处理后输出。其中:
编码器:将输入压缩成潜在空间表征。
解码器:重构潜在空间表征对其解码。
你可能会发现,上图中手写字符 4 被自动编码器处理后,看起来还是像手写字符 4。那么自动编码器到底有什么用处呢?
如果自动编码器的目的是重复输入和输出特征,那肯定是毫无用处的。事实上,我们希望通过训练输出值等于输入值的自动编码器,让潜在表征具有价值属性。与此同时,自动编码器完成了对输入特征的重构。所以,自动编码器同样有两个主要用途:数据去噪和数据可视化降维。
65.4. 基础自动编码器#
正式构建自动编码器之前,我们还需要进一步了解自动编码器网络的特点。首先,自动编码器中的编码器和解码器都是如下所示的全连接前馈神经网络结构。你可以自由定义两个神经网络的超参数,当然往往不一定是如下所示的对称结构。
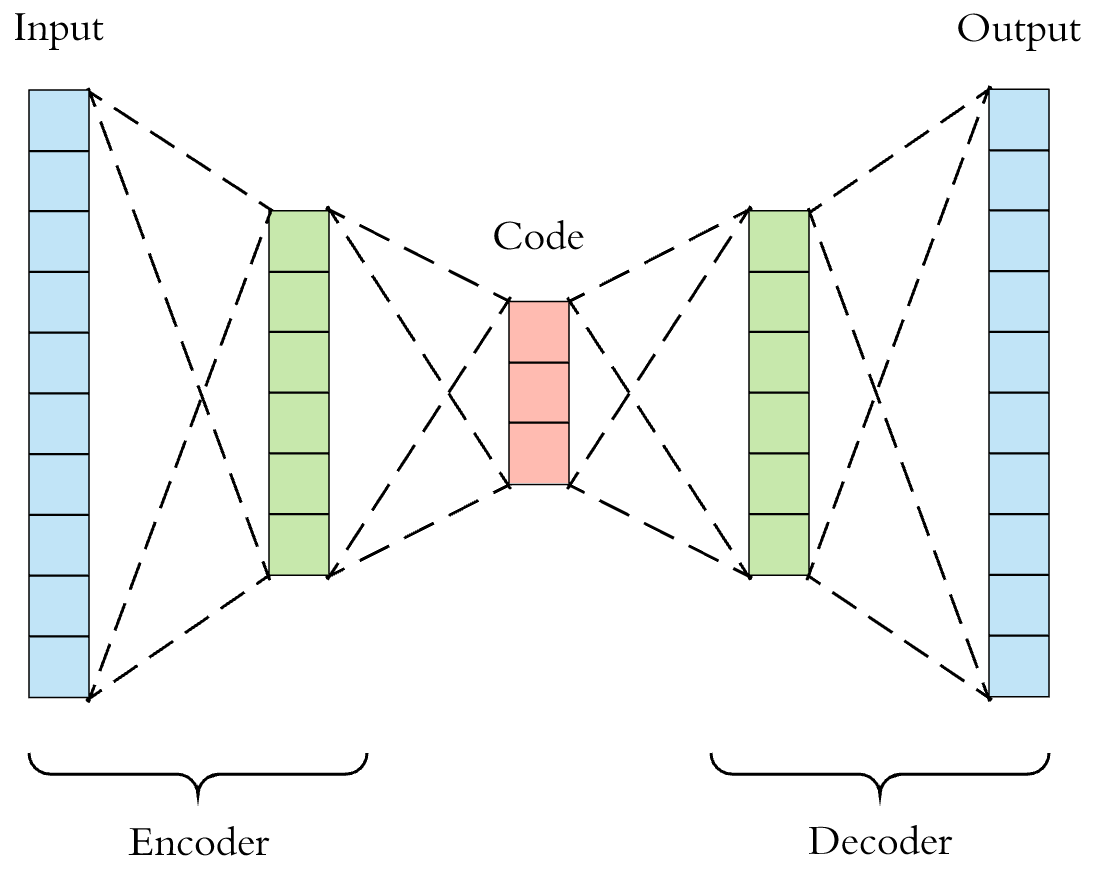
为了方便演示,实验使用大家熟悉的 MNIST 数据集。
下面,我们先使用 Keras 加载该数据集。同时,将手写字符图像展平并除以 255 完成归一化。为了提升训练速度,实验只选择 3 万个训练样本和 100 个测试样本。
import tensorflow as tf
(X_train, _), (X_test, _) = tf.keras.datasets.mnist.load_data()
X_train = X_train[:30000].reshape(-1, 28 * 28) / 255
X_test = X_test[:100].reshape(-1, 28 * 28) / 255
X_train.shape, X_test.shape
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
11490434/11490434 [==============================] - 2s 0us/step
((30000, 784), (100, 784))
接下来,我们构建一个极简单的基础自动编码器结构,其只包含 1 个隐含层。为了方便理清楚编码器和解码器的部分,实验不再使用 Keras 顺序模型,而是 函数模型 进行构建。
# 输出
input_ = tf.keras.layers.Input(shape=(784,))
# 编码器
encoded = tf.keras.layers.Dense(64, activation="relu")(input_)
# 解码器
decoded = tf.keras.layers.Dense(784, activation="sigmoid")(encoded)
# 建立函数模型,传入输入和输出层
model = tf.keras.models.Model(inputs=input_, outputs=decoded)
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 784)] 0
dense (Dense) (None, 64) 50240
dense_1 (Dense) (None, 784) 50960
=================================================================
Total params: 101200 (395.31 KB)
Trainable params: 101200 (395.31 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
经典的自动编码器结构中,一般编码器输出层会使用 Relu 激活,而解码器输出层会使用 Sigmoid 激活。所以,上面我们也沿用了这一结构。
接下来,我们尝试编译模型。其中,优化器选择熟悉的 Adam
就行,而损失函数则一般选择交叉熵或者均方误差
MSE。从经验的角度来讲,如果输入值在
\([0,1]\)
范围内,通常使用交叉熵损失函数
binary_crossentropy,否则使用均方误差。MNIST 数据集输入值本来在
\([0,255]\)
之间,因为我们已经完成了归一化操作,所以选择交叉熵损失函数。
model.compile(optimizer="adam", loss="binary_crossentropy")
最后,就是自动编码器的训练过程。值得注意的是,自动编码器的目标与输入相同,所以 Keras 中标签参数也传入特征即可。
model.fit(X_train, X_train, batch_size=64, epochs=10)
Epoch 1/10
469/469 [==============================] - 1s 1ms/step - loss: 0.2034
Epoch 2/10
469/469 [==============================] - 1s 1ms/step - loss: 0.1229
Epoch 3/10
469/469 [==============================] - 1s 1ms/step - loss: 0.1013
Epoch 4/10
469/469 [==============================] - 1s 2ms/step - loss: 0.0900
Epoch 5/10
469/469 [==============================] - 1s 1ms/step - loss: 0.0836
Epoch 6/10
469/469 [==============================] - 1s 1ms/step - loss: 0.0801
Epoch 7/10
469/469 [==============================] - 1s 1ms/step - loss: 0.0780
Epoch 8/10
469/469 [==============================] - 1s 1ms/step - loss: 0.0767
Epoch 9/10
469/469 [==============================] - 1s 1ms/step - loss: 0.0758
Epoch 10/10
469/469 [==============================] - 1s 1ms/step - loss: 0.0752
<keras.src.callbacks.History at 0x2968ba380>
下面,我们做两件事情,分别是:可视化测试数据通过编码器之后的 Code,以及可视化通过解码器重构之后的输出图像。
首先,要查看编码器的输出,我们需要定义编码器模型之后再进行推理。
from matplotlib import pyplot as plt
%matplotlib inline
n = 5
encoder = tf.keras.models.Model(input_, encoded) # 仅编码器模型
encoded_code = encoder.predict(X_test[:n]) # 编码器之后的 Code
# 可视化前 10 个测试样本编码之后的 Code
plt.figure(figsize=(10, 8))
for i in range(n):
ax = plt.subplot(1, n, i + 1)
plt.imshow(encoded_code[i].reshape(4, 16).T, cmap="gray")
ax.get_xaxis().set_visible(False) # 不显示坐标
ax.get_yaxis().set_visible(False)
1/1 [==============================] - 0s 29ms/step

上面展示了部分测试数据被训练好的编码器处理之后的 Code,当然这看起来就如同乱码一样。
但接下来,我们使用包含解码器的完整自动编码器对测试数据进行重构。下面对比测试样本和自动编码器输出的测试样本图像。
decoded_code = model.predict(X_test[:n]) # 自动编码器推理
plt.figure(figsize=(10, 6))
for i in range(n):
# 输出原始测试样本图像
ax = plt.subplot(3, n, i + 1)
plt.imshow(X_test[i].reshape(28, 28), cmap="gray")
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 输出自动编码器重构后的图像
ax = plt.subplot(3, n, i + n + 1)
plt.imshow(decoded_code[i].reshape(28, 28), cmap="gray")
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
1/1 [==============================] - 0s 17ms/step
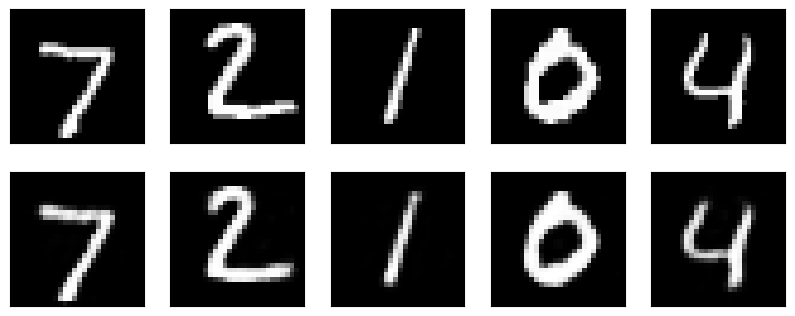
你会发现,解码器重构之后的输出结构和原结果非常相似了。那么这能说明什么呢?
实际上,前面的步骤即演示了如何使用自动编码器对数据进行降维(压缩)的流程。编码器将长度为 784 的原样本编码为长度为 64 的 Code,这就是将输入压缩成潜在空间表征的过程。而解码器实际上只是从长度为 64 的 Code 中就重构出了和原样本十分接近的图像。所以,我们是否就可以使用压缩后的特征来替代原样本特征呢?答案当然是肯定的。
65.5. 去噪自动编码器#
上面我们构建了一个基础自动编码器,并了解了自动编码器在数据降维方面的应用。接下来,实验将带你学习自动编码器的另一个经典场景:数据去噪。
首先,我们对上面的 MNIST
数据集添加随机的高斯噪声。思路很简单,先使用
np.random.normal
生成同尺寸的随机值,并与原数组进行求和。再使用
np.clip
将数组规约到
\([0, 1]\)
之间即可。
下面过程处理时间稍长,请耐心等待。
import numpy as np
X_train_ = X_train + 0.4 * np.random.normal(size=X_train.shape) # 添加同尺寸随机值
X_test_ = X_test + 0.4 * np.random.normal(size=X_test.shape)
X_train_noisy = np.clip(X_train_, 0, 1) # 将数组规约到 [0, 1] 之间
X_test_noisy = np.clip(X_test_, 0, 1)
X_train_noisy.shape, X_test_noisy.shape
((30000, 784), (100, 784))
下面,我们可视化添加随机噪声后的样本图像。
plt.figure(figsize=(10, 2))
for i in range(n):
ax = plt.subplot(1, n, i + 1)
plt.imshow(X_train_noisy[i].reshape(28, 28), cmap="gray")
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)

接下来,我们希望自动编码器能根据噪声图像重新生成原始图像。其流程如下图所示。
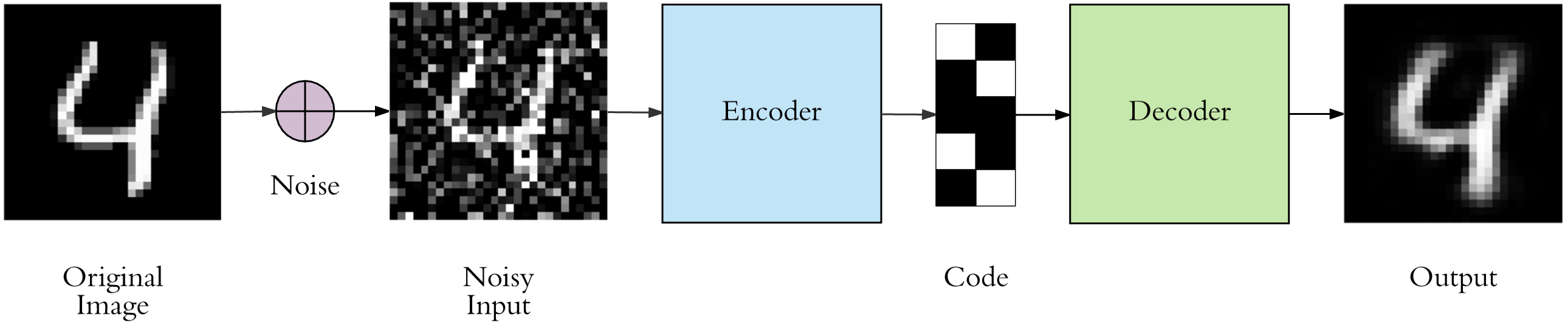
你可以修改上面的基础自动编码器使之变得复杂一些,当然这里也可以继续沿用上面定义好的基础自动编码器结构,稍有不同的是训练时的输入为噪声图像,而目标值则为原始图像。
model.fit(X_train_noisy, X_train, batch_size=64, epochs=10)
Epoch 1/10
469/469 [==============================] - 1s 1ms/step - loss: 0.1071
Epoch 2/10
469/469 [==============================] - 1s 1ms/step - loss: 0.1015
Epoch 3/10
469/469 [==============================] - 1s 2ms/step - loss: 0.1003
Epoch 4/10
469/469 [==============================] - 1s 2ms/step - loss: 0.0997
Epoch 5/10
469/469 [==============================] - 1s 2ms/step - loss: 0.0994
Epoch 6/10
469/469 [==============================] - 1s 2ms/step - loss: 0.0991
Epoch 7/10
469/469 [==============================] - 1s 2ms/step - loss: 0.0989
Epoch 8/10
469/469 [==============================] - 1s 1ms/step - loss: 0.0988
Epoch 9/10
469/469 [==============================] - 1s 1ms/step - loss: 0.0986
Epoch 10/10
469/469 [==============================] - 1s 1ms/step - loss: 0.0985
<keras.src.callbacks.History at 0x29ec05180>
接下来,实验使用测试数据中的噪声图像数据,经过训练好的自动编码器处理后看一下能不能成功去除噪声。
decoded_code = model.predict(X_test_noisy[:n]) # 自动编码器推理
plt.figure(figsize=(10, 6))
for i in range(n):
# 输出原始测试样本图像
ax = plt.subplot(3, n, i + 1)
plt.imshow(X_test_noisy[i].reshape(28, 28), cmap="gray")
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
# 输出自动编码器去噪后的图像
ax = plt.subplot(3, n, i + n + 1)
plt.imshow(decoded_code[i].reshape(28, 28), cmap="gray")
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
1/1 [==============================] - 0s 11ms/step

可以看到,结果还是不错的。经过训练之后的自动编码器已经成功去除了测试数据中的大部分噪声。当然,这里使用到的网络还是相对比较基础的,如果使用卷积自动编码器结构,效果会更好一些。
65.6. 总结#
本次实验中,我们了解了什么是自动编码器,以及如何去构建一个自动编码器。当然,实验也通过一个基础自动编码器结构来完成了对 MNIST 数据降维和去噪的过程。自动编码器目前发展的势头较好,尤其是更前沿,更复杂的 变分自动编码器,感兴趣的同学也可以自行去了解学习。
○ 欢迎分享本文链接到你的社交账号、博客、论坛等。更多的外链会增加搜索引擎对本站收录的权重,从而让更多人看到这些内容。