
44. 机器学习模型动态增量训练#
44.1. 介绍#
通过前面的实验内容,相信你已经对于使用 scikit-learn 保存、部署模型非常熟悉。本次挑战中,你会了解到什么是增量训练,以及动态增量模型的部署及调用。
44.2. 知识点#
动态模型
增量训练
实时手写字符识别
44.3. 静态模型和动态模型#
上一个实验中,我们了解到了如何将机器学习模型部署到线上,并完成动态推理。实际上,除了推理过程有动态和静态之分,机器学习模型的训练过程也有动态和静态两类。
-
静态模型采用离线训练方式。一般只训练模型一次,然后长时间使用该模型。
-
动态模型采用在线训练方式。数据会不断进入系统,通过不断地更新系统将这些数据整合到模型中。
前面的实验中,我们都采用了离线训练并保存静态模型的方式。而实际上,当你将一个机器学习模型部署到线上时,你可能会想让该模型动态学习更多新的数据,并持续更新。

上面的过程可以这样理解。离线训练使用大量的本地数据来训练模型,此时如果输入增量数据,模型会在已优化的参数条件下继续学习。这样的好处在于,模型是持续学习的过程,而不是每次都从头再来。
当然,想法是非常好的。但是并不是每一种模型都支持在线(增量)训练,这需要根据模型的自身的特征和所使用机器学习框架来决定。
scikit-learn 中,支持增量训练 的算法有:
-
分类算法
-
sklearn.naive_bayes.MultinomialNB -
sklearn.naive_bayes.BernoulliNB -
sklearn.linear_model.Perceptron -
sklearn.linear_model.SGDClassifier -
sklearn.linear_model.PassiveAggressiveClassifier -
sklearn.neural_network.MLPClassifier
-
-
回归算法
-
sklearn.linear_model.SGDRegressor -
sklearn.linear_model.PassiveAggressiveRegressor -
sklearn.neural_network.MLPRegressor
-
下面,我们使用人工神经网络来完成模型动态增量训练及部署过程。这里同样选择前面用过的 DIGITS 手写字符数据集。为了实验的需要,我们将手写字符矩阵中大于 0 的值全部替换为 1。
import warnings
warnings.filterwarnings("ignore")
from sklearn.datasets import load_digits
digits = load_digits() # 加载数据集
digits.data.shape, digits.target.shape
((1797, 64), (1797,))
然后,将数据集切分为训练集和测试数据集。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
digits.data, digits.target, random_state=1, test_size=0.2
)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
((1437, 64), (360, 64), (1437,), (360,))
接下来,使用 Train 数据训练模型,并使用测试数据评估。在
MLPClassifier 中添加
verbose=1
可以输出每一步迭代的损失值。
from sklearn.metrics import accuracy_score
from sklearn.neural_network import MLPClassifier
model = MLPClassifier(random_state=1, verbose=1, max_iter=50)
model.fit(X_train, y_train) # 训练模型
y_pred = model.predict(X_test) # 测试模型
accuracy_score(y_test, y_pred) # 准确度
Iteration 1, loss = 7.02205935
Iteration 2, loss = 3.65516147
Iteration 3, loss = 2.47679869
Iteration 4, loss = 1.49613624
Iteration 5, loss = 1.00259484
Iteration 6, loss = 0.72002813
Iteration 7, loss = 0.54341224
Iteration 8, loss = 0.43746627
Iteration 9, loss = 0.36224450
Iteration 10, loss = 0.30940686
Iteration 11, loss = 0.26808400
Iteration 12, loss = 0.23881533
Iteration 13, loss = 0.21317742
Iteration 14, loss = 0.19387023
Iteration 15, loss = 0.17858371
Iteration 16, loss = 0.16540074
Iteration 17, loss = 0.15237040
Iteration 18, loss = 0.14083022
Iteration 19, loss = 0.13015872
Iteration 20, loss = 0.12388636
Iteration 21, loss = 0.11475134
Iteration 22, loss = 0.10716270
Iteration 23, loss = 0.10093849
Iteration 24, loss = 0.09392212
Iteration 25, loss = 0.08891589
Iteration 26, loss = 0.08473752
Iteration 27, loss = 0.08024667
Iteration 28, loss = 0.07630452
Iteration 29, loss = 0.07093241
Iteration 30, loss = 0.06705022
Iteration 31, loss = 0.06426208
Iteration 32, loss = 0.06073862
Iteration 33, loss = 0.05743292
Iteration 34, loss = 0.05524405
Iteration 35, loss = 0.05257737
Iteration 36, loss = 0.04949237
Iteration 37, loss = 0.04771388
Iteration 38, loss = 0.04545686
Iteration 39, loss = 0.04306707
Iteration 40, loss = 0.04101056
Iteration 41, loss = 0.03913876
Iteration 42, loss = 0.03854201
Iteration 43, loss = 0.03717838
Iteration 44, loss = 0.03520881
Iteration 45, loss = 0.03329344
Iteration 46, loss = 0.03247741
Iteration 47, loss = 0.03017486
Iteration 48, loss = 0.02957126
Iteration 49, loss = 0.02897609
Iteration 50, loss = 0.02674436
0.975
可以看的,模型在测试集上得到约等于 98% 的准确度。下面,我们就找到那些被模型错误预测的样本。
n = 0
for i, (pred, test) in enumerate(zip(y_pred, y_test)):
if pred != test:
print("样本索引:", i, "被错误预测为: ", pred, "正确标签为: ", test)
n += 1
print("总计错误预测样本数量:", n)
样本索引: 21 被错误预测为: 4 正确标签为: 1
样本索引: 58 被错误预测为: 9 正确标签为: 5
样本索引: 88 被错误预测为: 9 正确标签为: 5
样本索引: 173 被错误预测为: 5 正确标签为: 8
样本索引: 208 被错误预测为: 4 正确标签为: 0
样本索引: 281 被错误预测为: 4 正确标签为: 0
样本索引: 321 被错误预测为: 4 正确标签为: 7
样本索引: 347 被错误预测为: 5 正确标签为: 8
样本索引: 348 被错误预测为: 3 正确标签为: 5
总计错误预测样本数量: 9
现在,可以使用 Matplotlib 绘制出被错误预测的样本,看看是不是容易被混淆。
from matplotlib import pyplot as plt
%matplotlib inline
plt.imshow(X_test[108].reshape((8, 8)), cmap=plt.cm.gray_r)
<matplotlib.image.AxesImage at 0x14784ba00>
随意挑选几个错误预测样本打印,你会发现的确连人眼都不容易分清楚。
44.4. 动态增量训练#
既然,当然训练的模型存在错误预测结果,那么如果我们让模型来学习这些样本,并人为告诉它正确结果,模型不就完成了增量训练了吗?
scikit-learn 中,增量训练的方法是
model.partial_fit(X,
y),其使用方法与
model.fit(X,
y)
别无二致。
接下来,我们就利用上面已经训练好的模型,对错误预测样本进行增量学习。
import numpy as np
addition_index = []
for i, (pred, test) in enumerate(zip(y_pred, y_test)):
if pred != test:
addition_index.append(i)
addition_X = X_test[addition_index] # 错误预测样本特征
addition_y = y_test[addition_index] # 错误预测样本正确标签
# 增量训练模型
model.partial_fit(addition_X, addition_y)
model
Iteration 51, loss = 2.24865593
MLPClassifier(max_iter=50, random_state=1, verbose=1)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
MLPClassifier(max_iter=50, random_state=1, verbose=1)
下面,我们重新使用模型来对测试数据进行预测,并重新打印出错误预测的样本。
y_pred = model.predict(X_test) # 测试模型
accuracy_score(y_test, y_pred) # 准确度
# 打印错误预测样本
n = 0
for i, (pred, test) in enumerate(zip(y_pred, y_test)):
if pred != test:
print("样本索引:", i, "被错误预测为: ", pred, "正确标签为: ", test)
n += 1
print("总计错误预测样本数量:", n)
样本索引: 75 被错误预测为: 6 正确标签为: 4
样本索引: 88 被错误预测为: 9 正确标签为: 5
样本索引: 172 被错误预测为: 8 正确标签为: 3
样本索引: 173 被错误预测为: 5 正确标签为: 8
样本索引: 229 被错误预测为: 2 正确标签为: 3
样本索引: 248 被错误预测为: 8 正确标签为: 3
样本索引: 249 被错误预测为: 5 正确标签为: 7
样本索引: 281 被错误预测为: 4 正确标签为: 0
样本索引: 347 被错误预测为: 5 正确标签为: 8
总计错误预测样本数量: 9
可以看的,错误预测样本的总数减少了。不过,部分样本依旧无法正确预测,且由于增量学习样本的输入,导致模型参数的整体变动,所以也可能发生之前正确预测的样本被错误预测的现象。
当然,如果错误预测样本总数并未减少,就可以多次重复执行上方两个单元格让模型不断学习错误样本,应该能看到更为直观的效果。
接下来,我们完成一个有意思的过程。实验打算构建一个可以部署到线上的手写字符识别系统,使之可以实现对用户绘制的字符进行预测。
实验预先实现一段代码,使你可以在 Jupyter Notebook 环境中手动绘制一个字符。直接运行下面单元格即可。
from IPython.display import HTML
input_form = """
<table>
<td style="border-style: none;">
<div style="border: solid 2px #666; width: 43px; height: 44px;">
<canvas width="40" height="40"></canvas>
</div></td>
<td style="border-style: none;">
<button onclick="clear_value()">重绘</button>
</td>
</table>
"""
javascript = """
<script type="text/Javascript">
var pixels = [];
for (var i = 0; i < 8*8; i++) pixels[i] = 0;
var click = 0;
var canvas = document.querySelector("canvas");
canvas.addEventListener("mousemove", function(e){
if (e.buttons == 1) {
click = 1;
canvas.getContext("2d").fillStyle = "rgb(0,0,0)";
canvas.getContext("2d").fillRect(e.offsetX, e.offsetY, 5, 5);
x = Math.floor(e.offsetY * 0.2);
y = Math.floor(e.offsetX * 0.2) + 1;
for (var dy = 0; dy < 1; dy++){
for (var dx = 0; dx < 1; dx++){
if ((x + dx < 8) && (y + dy < 8)){
pixels[(y+dy)+(x+dx)*8] = 1;
}
}
}
} else {
if (click == 1) set_value();
click = 0;
}
});
function set_value(){
var result = ""
for (var i = 0; i < 8*8; i++) result += pixels[i] + ","
var kernel = IPython.notebook.kernel;
kernel.execute("image = [" + result + "]");
kernel.execute("f = open('digits.json', 'w')");
kernel.execute("f.write('{\\"inputs\\":%s}' % image)");
kernel.execute("f.close()");
}
function clear_value(){
canvas.getContext("2d").fillStyle = "rgb(255,255,255)";
canvas.getContext("2d").fillRect(0, 0, 40, 40);
for (var i = 0; i < 8*8; i++) pixels[i] = 0;
}
</script>
"""
randint = np.random.randint(0, 9)
print(f"请在下方图框中细心绘制手写字符 {randint}")
HTML(input_form + javascript)
请在下方图框中细心绘制手写字符 2
|
|
由于输入框较小,你可以通过放大浏览器页面用鼠标进行书写。绘制的字符会自动保存存为
digits.json
文件到当前目录下方。然后,我们读取该文件,并将图像绘制出来。
import json
import numpy as np
with open("digits.json") as f:
inputs = f.readlines()[0]
inputs_array = np.array(json.loads(inputs)["inputs"])
plt.imshow(inputs_array.reshape((8, 8)), cmap=plt.cm.gray_r)
<matplotlib.image.AxesImage at 0x16307e320>
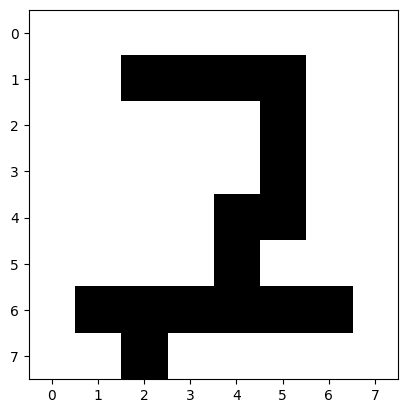
你会发现,由于 DIGITS 数据集的图像分辨率为
\(8 \times 8\)
像素,处理之后的图像会与绘制图像稍有区别。于此同时,因为我们上方绘制的图像为
2 值图像,即黑色像素数值存为 1,白色像素存为
0。所以,下面我们需要重新训练 DIGITS 模型,使之匹配。我们将
digits.data
中大于 0 的值全部替换为 1,并使用全部数据用于训练。
# 重新训练神经网络
digits.data[digits.data > 0] = 1
model = MLPClassifier(tol=0.001, max_iter=50, verbose=1)
model.fit(digits.data, digits.target)
Iteration 1, loss = 2.22309482
Iteration 2, loss = 1.98611114
Iteration 3, loss = 1.77759516
Iteration 4, loss = 1.57927044
Iteration 5, loss = 1.38663125
Iteration 6, loss = 1.20774216
Iteration 7, loss = 1.05083426
Iteration 8, loss = 0.92058288
Iteration 9, loss = 0.82050522
Iteration 10, loss = 0.73771197
Iteration 11, loss = 0.67522434
Iteration 12, loss = 0.61926095
Iteration 13, loss = 0.57464139
Iteration 14, loss = 0.53840080
Iteration 15, loss = 0.50641056
Iteration 16, loss = 0.47852272
Iteration 17, loss = 0.45534865
Iteration 18, loss = 0.43354940
Iteration 19, loss = 0.41585885
Iteration 20, loss = 0.39885888
Iteration 21, loss = 0.38530286
Iteration 22, loss = 0.37004597
Iteration 23, loss = 0.35894133
Iteration 24, loss = 0.34725008
Iteration 25, loss = 0.33895579
Iteration 26, loss = 0.32783111
Iteration 27, loss = 0.32029436
Iteration 28, loss = 0.31536069
Iteration 29, loss = 0.30647274
Iteration 30, loss = 0.29730023
Iteration 31, loss = 0.28933556
Iteration 32, loss = 0.28507046
Iteration 33, loss = 0.27861768
Iteration 34, loss = 0.27280789
Iteration 35, loss = 0.26719081
Iteration 36, loss = 0.26241597
Iteration 37, loss = 0.25833709
Iteration 38, loss = 0.25386779
Iteration 39, loss = 0.24923674
Iteration 40, loss = 0.24560314
Iteration 41, loss = 0.24193601
Iteration 42, loss = 0.23912347
Iteration 43, loss = 0.23715456
Iteration 44, loss = 0.23219586
Iteration 45, loss = 0.22928455
Iteration 46, loss = 0.22426162
Iteration 47, loss = 0.22252067
Iteration 48, loss = 0.21962222
Iteration 49, loss = 0.21669993
Iteration 50, loss = 0.21438963
MLPClassifier(max_iter=50, tol=0.001, verbose=1)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
MLPClassifier(max_iter=50, tol=0.001, verbose=1)
下面,就可以用刚刚训练好的模型来预测自行绘制的手写字符了。我们对每次预测结果进行增量训练来改善模型。如果预测正确,增量训练可以将此样本纳入模型中。如果预测错误,增量训练依据可以起到持续改善模型的效果。
inputs_array = np.atleast_2d(inputs_array) # 将其处理成 2 维数组
result = model.predict(inputs_array) # 预测
if result != randint:
print(f"预测错误|预测标签: {result}|真实标签: {randint}")
model.partial_fit(inputs_array, np.atleast_1d(randint))
print("完成增量训练")
else:
print(f"预测正确|预测标签: {result}|真实标签: {randint}")
model.partial_fit(inputs_array, np.atleast_1d(randint))
print("完成增量训练")
预测正确|预测标签: [2]|真实标签: 2
Iteration 51, loss = 0.19804450
完成增量训练
由于神经网络可以输出不同标签预测的概率,所以最后看一下网络对输入图像属于类别的评判依据。
# 输出神经网络对各类别的概率值
pred_proba = model.predict_proba(np.atleast_2d(inputs_array))
# 绘制柱形图
plt.xticks(range(10))
plt.bar(range(10), pred_proba[0], align="center")
<BarContainer object of 10 artists>
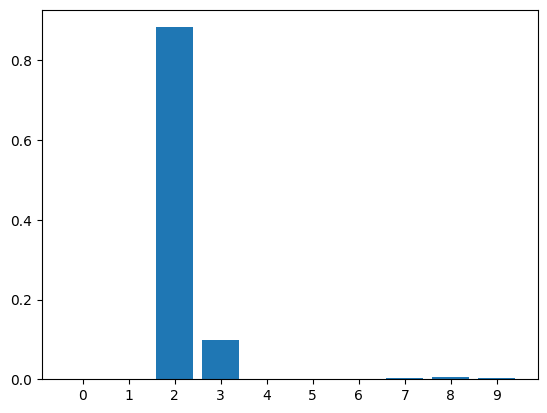
上方柱形图值越大,即代表网络认为输入图像属于该类别的概率更高。
特别说明的是,你可以尝试多次重复执行上方两个单元格,即反复增量训练自定义手写字符,应该可以看到增量训练使得正确标签的概率越来越高,这就是通过增量训练来优化模型的直观效果。
44.5. 总结#
本次实验中,我们了解了机器学习模型的静态训练和动态训练过程,特别对动态增量训练进行了学习。增量训练在机器学习工程领域有广泛应用,部署在线上的模型需要持续不断地改善才会越来越好。
实际上,你可以借助于前面模型部署的思路来实现一个线上实时手写字符识别应用。并收集每次识别的结果对模型进行增量训练。当然,这需要你对 Flask 等 Web 框架有熟悉的了解,有兴趣可以 学习此示例。
相关链接
○ 欢迎分享本文链接到你的社交账号、博客、论坛等。更多的外链会增加搜索引擎对本站收录的权重,从而让更多人看到这些内容。