
20. 决策树模型参数优化及选择#
20.1. 介绍#
决策树的实验中,我们从头开始实现了完整的决策树分类过程。当然,实验的最后也介绍了使用 scikit-learn 完成决策树建模。实际上,由于决策树存在剪枝过程,所涉及的的参数非常多,本次挑战将带领你搞定机器学习模型参数优化及选择。
20.2. 知识点#
CART 决策树分类
网格搜索参数选择
估计你早有这样的疑问,那就当我们构建机器学习模型时,怎样确定合适的参数?难道只能使用默认参数?或者盲目修改?
本次挑战将带你来找寻如何确定合适参数的答案。实际上,有的时候我们是能够估计模型参数或优化方法参数的大致范围,或者经过几次简单的手动修改来观测输出或评价指标变化,从而找到合适的参数。
但是,有的时候通过数次随机尝试来确定参数是不现实的。例如,决策树建模过程中涉及到的一些参数,最大深度,最大叶节点数等多个参数相互影响时,就变成了极其麻烦的排列组合。
下面,我们将介绍两种常用的超参数选择方法:网格搜索和随机参数。
20.3. 网格搜索#
网格搜索,简单来讲就是预先制定好各参数的有限个候选取值,然后通过排列组合的方式来传入这些参数,最终通过 K 折交叉验证的方法来确定表现最好的参数。
首先,我们来讲一下什么是 K 折交叉验证。K 折交叉验证是交叉验证中的一种常见方法,其通过将数据集均分成 K 个子集,并依次将其中的 K-1 个子集作为训练集,剩下的 1 个子集用作测试集。在 K 折交叉验证的过程中,每个子集均会被验证一次。
下面通过一张图示来解释 K 折交叉验证的过程:
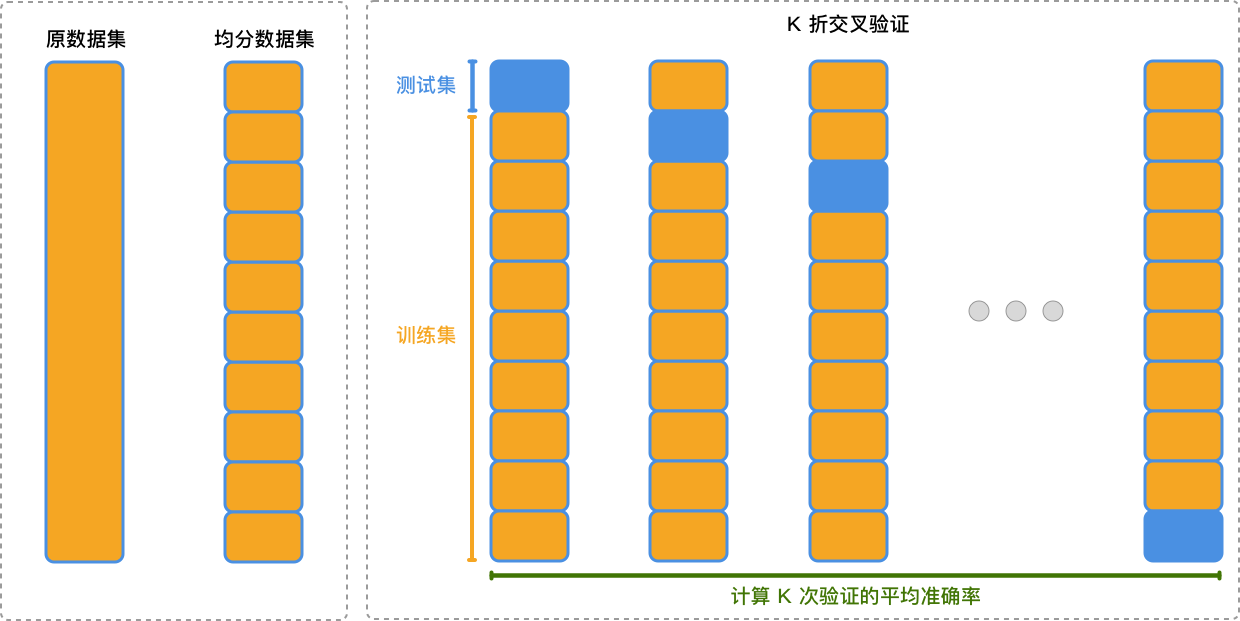
如上图所示,使用 K 折交叉验证的步骤如下:
首先将数据集均分为 K 个子集。
-
依次选取其中的 K-1 个子集作为训练集,剩下的 1 个子集用作测试集进行实验。
计算每次验证结果的平均值作为最终结果。
相比于手动划分数据集,K 折交叉验证让每一条数据都有均等的几率被用于训练和验证,在一定程度上能提升模型的泛化能力。关于交叉验证,后面会有更多介绍,本次挑战只需要通过指定参数即可完成。
回到网格搜索的定义中。例如,模型有参数 A 和参数 B,我们指定参数 A 有 \(P1\),\(P2\),\(P3\) 等 3 个参数,参数 B 有 \(P4\),\(P5\),\(P6\) 等 3 个参数。那么,通过排列组合有 9 种不同的情况。于是,就可以通过遍历来测试不同参数组合下模型的表现,得到最佳结果。

下面,我们先建立一个决策树分类模型。这里使用 scikit-learn 提供的 digits 数据集,该数据集已经在前面介绍过了。当然后续你可以使用自己的数据集进行练习。
from sklearn.datasets import load_digits
digits = load_digits()
digits.data.shape, digits.target.shape
((1797, 64), (1797,))
接下来,使用 scikit-learn 提供的决策树算法实现分类。
Exercise 20.1
挑战:建立 CART 决策树完成分类,并得到 5 折交叉验证结果的平均分类准确度。
规定:除设置
random_state=42
外,其他使用方法提供的默认参数。
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
## 代码开始 ### (≈3 行代码)
model = None
## 代码结束 ###
参考答案 Exercise 20.1
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
### 代码开始 ### (≈3 行代码)
model = DecisionTreeClassifier(random_state=42)
cvs = cross_val_score(model, digits.data, digits.target, cv=5)
np.mean(cvs)
### 代码结束 ###
期望输出
≈ 0.7903
下面,我们准备使用网格搜索方法对决策树分类中常用的参数进行调参。通过上面的网格搜索示例可知,网格搜索可以通过循环搞定,但是这里我们直接使用
scikit-learn 提供的
GridSearchCV
方法来实现。
Exercise 20.2
挑战:学习并使用
GridSearchCV
完成网格搜索参数选择,并最终得到 5
等分交叉验证最佳结果。
规定:针对 CART 决策树
min_samples_split
搜索候选参数
[2,
10,
20],及
min_samples_leaf
搜索候选参数
[1,
5,
10]。其他参数未特别指明,使用默认即可。
自行阅读学习:GridSearchCV 官方文档|GridSearchCV 官方示例
from sklearn.model_selection import GridSearchCV
## 代码开始 ### (≈3 行代码)
gs_model = None
## 代码结束 ###
参考答案 Exercise 20.2
from sklearn.model_selection import GridSearchCV
### 代码开始 ### (≈3 行代码)
# 需搜索参数字典
tuned_parameters = {"min_samples_split": [2, 10, 20],
"min_samples_leaf": [1, 5, 10]}
# 网格搜索模型
gs_model = GridSearchCV(model, tuned_parameters, cv=5)
gs_model.fit(digits.data, digits.target)
### 代码结束 ###
运行测试
gs_model.best_score_ # 输出网格搜索交叉验证最佳结果
期望输出
≈ 0.790
实际上,你还可以通过模型的一些属性输出相关信息。例如下面查看网格搜索后的最佳参数。
gs_model.best_estimator_ # 查看网格搜索最佳参数
20.4. 随机搜索#
网格搜索很直观,也很方便,但是最大的问题在于随着候选参数增多,搜索需要的时间迅速增加。所以,有时候我们也会使用随机搜索的方法。
随机搜索,顾名思义就是经验 + 运气的碰撞。我们依据经验制定一个参数范围,然后在范围内随机选取参数测试,并返回最佳结果。例如下面,我们制定参数 A 在 \([P1, P3]\) 区间,参数 B 在 \([P4, P6]\) 区间变化。

scikit-learn 同样提供的
RandomizedSearchCV
方法来实现随机搜索。
Exercise 20.3
挑战:学习并使用
RandomizedSearchCV
完成网格搜索参数选择,并最终得到 5
等分交叉验证最佳结果。
规定:针对 CART 决策树
min_samples_split
搜索候选参数区间
(2,
20),及
min_samples_leaf
搜索候选参数区间
(1,
10),并随机搜索 10
组参数。其他参数未特别指明,使用默认即可。
自行阅读学习:RandomizedSearchCV 官方文档|RandomizedSearchCV 官方示例
from scipy.stats import randint
from sklearn.model_selection import RandomizedSearchCV
## 代码开始 ### (≈3 行代码)
rs_model = None
## 代码结束 ###
参考答案 Exercise 20.3
from scipy.stats import randint
from sklearn.model_selection import RandomizedSearchCV
### 代码开始 ### (≈3 行代码)
# 需搜索参数字典
tuned_parameters = {"min_samples_split": randint(2, 20),
"min_samples_leaf": randint(1, 10)}
# 随机搜索模型
rs_model = RandomizedSearchCV(model, tuned_parameters, n_iter=10, cv=5)
rs_model.fit(digits.data, digits.target)
### 代码结束 ###
rs_model.best_score_ # 输出网格搜索交叉验证最佳结果
rs_model.best_estimator_ # 查看网格搜索最佳参数
由于随机搜索每次结果不同,所以此处没有期望输出。
你可能会发现,我们使用网格搜索或随机搜索确定的参数往往还没有一开始的默认参数好。其实,scikit-learn 迭代到今天已经非常成熟,部分默认参数都是许多人在日常使用中总结而来的,所以往往默认参数表现就非常不错。调参在机器学习建模中很重要,但数据和相关预处理方法对于模型的最终表现往往更加重要。
○ 欢迎分享本文链接到你的社交账号、博客、论坛等。更多的外链会增加搜索引擎对本站收录的权重,从而让更多人看到这些内容。