
68. YOLO 图像目标检测应用#
68.1. 介绍#
YOLO 是区别于 R-CNN 的另一类常用目标检测方法。本次挑战中,你需要独立尝试利用相关的工具,来使用 YOLO 完成目标检测应用。
68.2. 知识点#
图像目标检测
YOLO 实时检测方法
Note
本挑战前半部分内容可沿用实验的方法进行学习。
2015 年,YOLO 方法被提出。2018 年,YOLO 已发展为 Version 3 版本。YOLOv3 的检测速度非常快,根据作者在 相关论文 中的实验结果,YOLOv3 比 R-CNN 快 1000 倍以上,比快速 R-CNN 快 100 倍。
本次挑战的前半部分将体验使用 YOLOv3 预训练模型的目标检测效果。挑战预先提供了 YOLOv3 使用 PyTorch 构建的网络,并在 COCO 数据集上训练了精简版的预训练模型。挑战直接克隆 YOLOv3 的实现代码。
!git clone "https://github.com/huhuhang/yolov3"
import sys
import warnings
warnings.filterwarnings('ignore')
sys.path.append("yolov3") # 添加路径
首先,下载 YOLOv3 在 COCO 上的预训练模型。
import os
from yolov3.utils import download_trained_weights
download_trained_weights("yolov3_tiny_coco_01.h5") # 下载预训练模型
然后,我们使用定义好的网络,并加载预训练模型
yolov3_tiny_coco_01.h5。
import torch
from yolov3.yolov3_tiny import Yolov3Tiny
model = Yolov3Tiny(num_classes=80) # COCO 数据集类别
model.load_state_dict(torch.load('yolov3_tiny_coco_01.h5'))
接下来,使用预先定义好的一些功能函数来读取并处理测试图片。实际上就是将图片读取成数值,裁剪形状以及转换为 PyTorch 张量类型。需要注意,该预训练网络只支持传入 \([1, 3, n*32, n*32]\) 形状的图片张量,也就是长宽像素必须为 32 的倍数。
from yolov3.utils import Image, image2torch
img_org = Image.open("yolov3/test.png").convert('RGB') # 读取图片
img_resized = img_org.resize((992, 480)) # 裁剪大小
img_torch = image2torch(img_resized) # 转换为张量
img_torch.shape
紧接着,就可以执行目标检测,这里调用
predict_img
方法。该方法可以直接返回边界框的坐标参数。其中,可以设置最低置信度
conf_thresh,过滤掉大部分不必要的边界框。
all_boxes = model.predict_img(img_torch, conf_thresh=0.3)[0]
len(all_boxes) # 边界框数量
下面,我们可以将边界框绘制到图中。同样需要定义 COCO 数据集类别名称。
# COCO 类别名称,顺序相关
class_names = ['person', 'bicycle', 'car', 'motorcycle', 'airplane',
'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird',
'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear',
'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie',
'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard',
'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup',
'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed',
'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote',
'keyboard', 'cell phone', 'microwave', 'oven', 'toaster',
'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush']
最终,使用预先定义好的
plot_img_detections
绘制出边界框。
from yolov3.utils import plot_img_detections
plot_img_detections(img_resized, all_boxes,
figsize=(16, 8), class_names=class_names)
应该可以直观感觉到 YOLOv3 的速度的确远远快于之前实验中使用 R-CNN 来做目标检测。上面的内容,我们使用了 PyTorch 构建的 YOLOv3。这部分代码较多,所以没有用于挑战,如果感兴趣可以阅读源码。
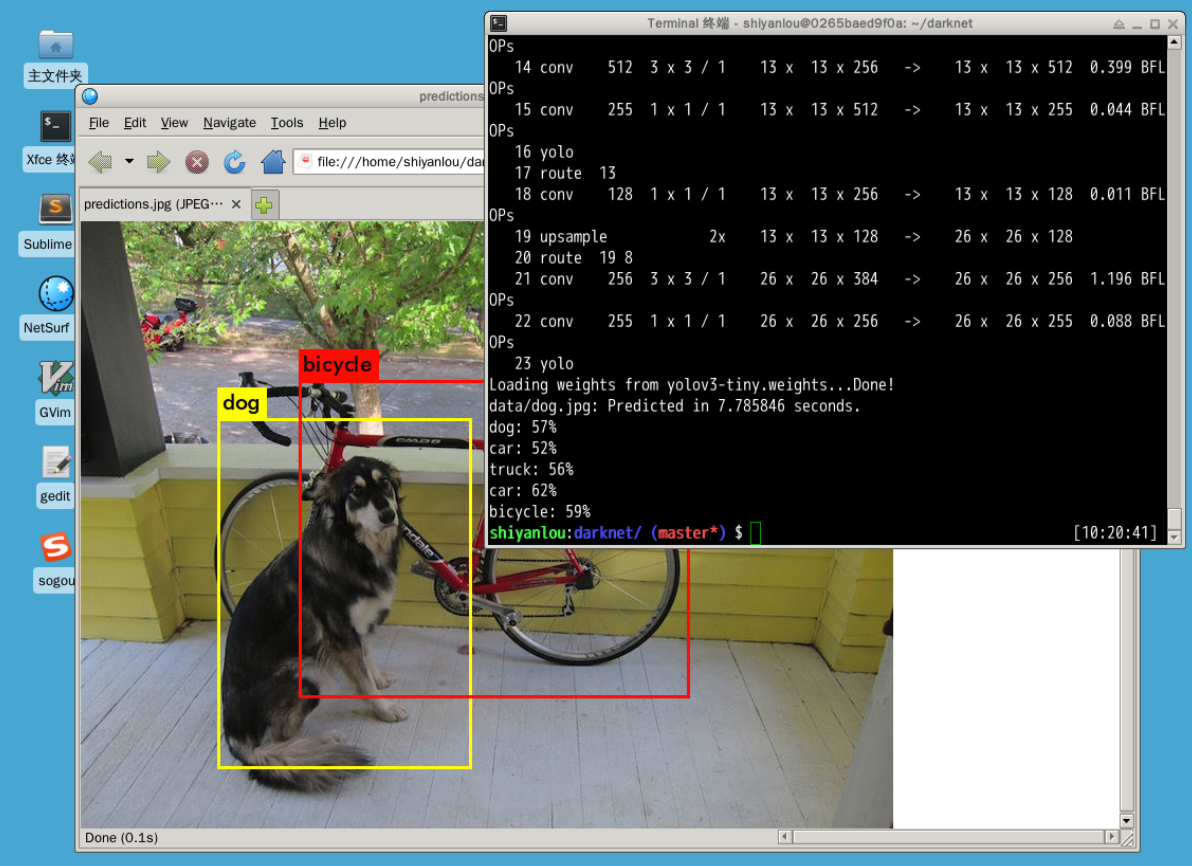
实际上,YOLOv3 本身也提供了一个叫 Darknet 的工具,该工具可以很方便地用于训练和测试使用 YOLOv3 构建的目标检测模型。Darknet 使用 C 语言开发,执行效率极高。线上 Notebook 使用 Darknet 的体验不好,所以接下来的挑战是希望你能够自行在 Linux 桌面环境中熟悉 Darknet 的使用。
Exercise 68.1
开放型挑战
挑战:请自学 Darknet 工具的使用,并根据开发者提供的入门资料完成目标检测示例过程。
提示:请阅读开发者提供的 快速入门指南,使用其提供的预训练模型对任意图片进行目标检测。推荐你使用 Linux 完成该挑战,并合理利用搜索引擎排除使用过程中遇到的问题
Darknet 开发者提供的预训练模型下载速度较慢,挑战提供了镜像下载地址。
# 预训练模型镜像下载链接
https://cdn.aibydoing.com/aibydoing/files/yolov3.weights
https://cdn.aibydoing.com/aibydoing/files/yolov3-tiny.weights
期望输出
○ 欢迎分享本文链接到你的社交账号、博客、论坛等。更多的外链会增加搜索引擎对本站收录的权重,从而让更多人看到这些内容。