
30. 密度聚类标记异常共享单车#
30.1. 介绍#
本次挑战将考察密度聚类的应用。我们将尝试使用密度聚类可视化共享单车位置分布,同时使用不同的参数来标记出异常共享单车的位置。
30.2. 知识点#
DBSCAN 参数确定
HDBSCAN 聚类
如今,共享单车已经遍布大街小巷,的确方便了市民的短距离出行。不过,如果你是一家共享单车公司的运营,是否会考虑这样一个问题,那就是公司投放到城市中的共享单车都去哪里了呢?
当然,这个问题并不是为了满足你的好奇心,而是通过追踪共享单车的分布状况及时调整运营策略。比如,有一些位置的单车密度过高,那么就应该考虑将其移动到一些密度低但有需求的区域。
所以,今天的挑战中,将会使用到密度聚类方法来追踪共享单车的分布情况。
我们获取到北京市某一区域的共享单车 GPS
散点数据集,该数据集名称为
challenge-9-bike.csv。首先,加载并预览该数据集。
wget -nc https://cdn.aibydoing.com/aibydoing/files/challenge-9-bike.csv
import pandas as pd
import numpy as np
df = pd.read_csv("challenge-9-bike.csv")
df.describe()
| lat | lon | |
|---|---|---|
| count | 3000.000000 | 3000.000000 |
| mean | 39.908308 | 116.474630 |
| std | 0.007702 | 0.018098 |
| min | 39.893939 | 116.434264 |
| 25% | 39.902769 | 116.461276 |
| 50% | 39.907888 | 116.477683 |
| 75% | 39.914482 | 116.490274 |
| max | 39.923023 | 116.501467 |
其中,lat
是 latitude 的缩写,表示纬度,lon
是 longitude 的缩写,表示经度。于是,我们就可以通过
Matplotlib 绘制出该区域共享单车的分布情况。
from matplotlib import pyplot as plt
%matplotlib inline
plt.figure(figsize=(15, 8))
plt.scatter(df["lat"], df["lon"], alpha=0.6)
<matplotlib.collections.PathCollection at 0x121cb4ac0>

接下来,我们尝试使用 DBSCAN 密度聚类算法对共享单车进行聚类,看一看共享单车高密度区域的分布情况。(可能会失效,对挑战无影响)
根据前一节实验可知,DBSCAN 算法的两个关键参数是
eps
和密度阈值
MinPts。那么这两个值设定为多少比较合适呢?
Exercise 30.1
挑战:使用 DBSCAN 算法完成共享单车 GPS
散点数据密度聚类,需要确定
eps
和
min_samples
参数。
规定:假设半径 100 米范围内有 10 辆车为高密度区域。
提示:挑战以纬度变化为参考,初略估算纬度变化 1 度,对应该区域 100km 的地面距离。
from sklearn.cluster import DBSCAN
## 代码开始 ### (≈ 2 行代码)
## 代码结束 ###
dbscan_c # 输出聚类标签
运行测试
np.mean(dbscan_c)
期望输出
6.977333333333333
Exercise 30.2
挑战:针对上面聚类后数据,按要求重新绘制散点图。
规定:未被聚类的异常点以
alpha=0.1
蓝色数据点呈现,聚类数据按类别呈现且设置
cmap='viridis'。
## 代码开始 ### (≈ 4~8 行代码)
plt.figure(figsize=(15, 8))
## 代码结束 ###
期望输出
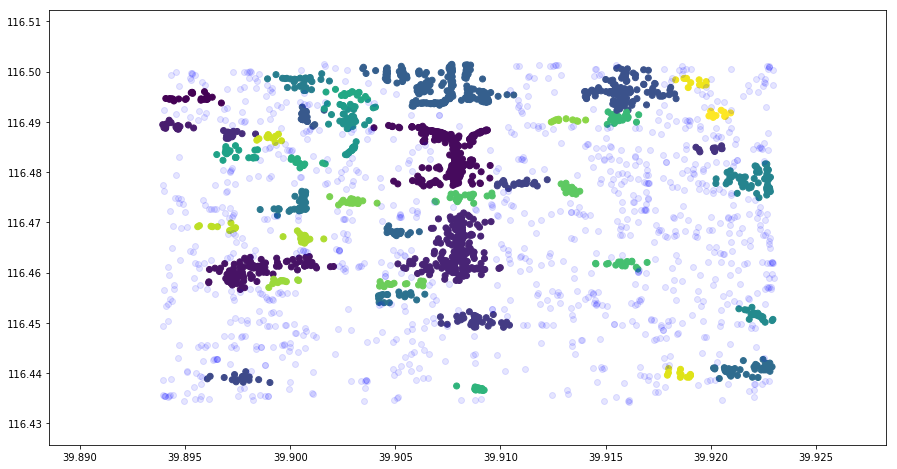
从上图可以看出,不同区域的单车密度分布情况。
HDSCAN 算法很多时候不仅仅是完成聚类,由于其本身的特性,很多时候还用其识别异常点。在本次实验中,我们同样可以通过调节参数来识别位置异常的共享单车。
Exercise 30.3
挑战:针对聚类后数据,将异常点(不符合半径 100 米内有 2 辆共享单车)绘制到散点图。
规定:未被聚类的边界点以红色数据点呈现,聚类数据按类别呈现且设置
alpha=0.1,cmap='viridis'。
## 代码开始 ### (≈ 6~10 行代码)
plt.figure(figsize=(15, 8))
## 代码结束 ###
期望输出
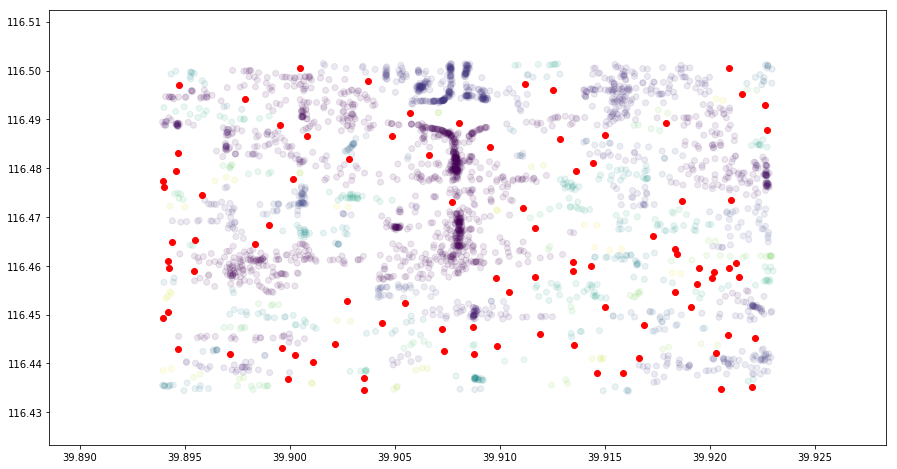
本次挑战主要是了解了如何快速确定 DBSCAN 初始参数以及使用该算法标记离群点的方法。如果你有兴趣,还可以自行尝试使用 HDBSCAN 聚类,并对比二者的聚类效果。当然,在这之前你需要先使用实验中的方法安装 hdbscan 模块。
○ 欢迎分享本文链接到你的社交账号、博客、论坛等。更多的外链会增加搜索引擎对本站收录的权重,从而让更多人看到这些内容。