
84. 强化学习介绍与示例#
84.1. 介绍#
强化学习(英语:Reinforcement learning,简称:RL)是非常前沿的学科,它可能是实现强(类)人工智能的手段之一。了解并掌握基础的强化学习方法,将使得你对人工智能的概念进一步深化。
84.2. 知识点#
强化学习介绍
强化学习算法分类
强化学习应用
课外内容推荐
84.3. 强化学习介绍#
机器学习通常被划分为 4 个大分支,分别是:监督学习、非监督学习、半监督学习以及强化学习。本次课程中,我们将对强化学习的概念进行介绍并完成算法应用实践。由于课程涉及内容难度较高,需要你已经基础的机器学习知识。
强化学习强调如何基于环境而行动,以取得最大化的预期利益。强化学习是一门正在快速发展的分支学科,许多科学家都认为其可能是实现强人工智能(通用人工智能)的途径之一。
强化学习的过程一般包含 5 个要素,分别是:智能体(Agent)、环境(Environment)、行为(Action)、状态(State)、奖励(Reward)。几者之间的关系如下:
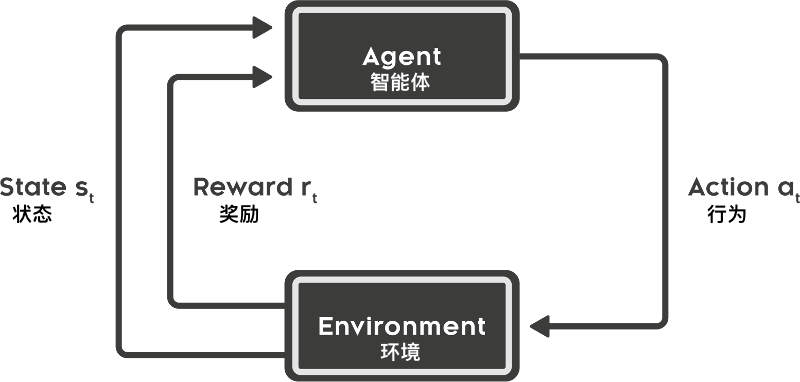
下面,我们通过一个迷宫示例来介绍强化学习的 5 个要素具体的含义。

如上图所示,假设小狮子想要通过强化学习走出一个迷宫。首先,小狮子就是智能体(Agent),而迷宫就是所处的环境(Environment)。
当小狮子尝试走出迷宫时,它站在每一个格子上都可以产生 4 种行为(Action),即向上、向下、向左、向右。当每一种行为作用在环境上时,迷宫会反馈给小狮子一个奖励。奖励可以是积极的(正奖励)或者消极的(负奖励)。例如,我们一般会将出口处设置一个很大的正奖励,以便于小狮子找到迷宫的出口。
那么,什么是状态(State)呢?每当小狮子采取行动之后,随即进入到下一个 State。State 类似于对前面历史行为的总结,用于指导下一次行为。而 State 如何去总结历史行为呢,这就涉及到马尔可夫决策过程,我们将在实验中详细阐述。
接下来,小狮子就会在迷宫中不断地试错并最终找到出口,到达出口时也就是正奖励之和最大的时候。
最后,我们通过小狮子走迷宫来重新总结一下强化学习的过程:小狮子(Agent)在环境(Environment)中通过不断地执行某个行动(Action), 然后转入下一个状态(State), 并得到来自环境(Environment)的回报(Reward),进而更新训练 Agent。
这里需要补充一点,强化学习中的奖励反馈往往是延迟的,因为你可能走很多步才会得到一个正奖励或者负奖励。这也是强化学习的重要特点之一。
84.4. 强化学习与监督学习的区别#
看完上面典型的强化学习的过程介绍,你可能会想到它和监督学习有何区别?
简单来讲,监督学习是通过从有标签的已知数据中寻找规律并对未知数据进行预测的过程。而强化学习则是主动学习,且根据从环境中得到的反馈回报,不断变聪明的过程。
其实,在监督学习中,数据集也可以被当作是环境,只不过我们一开始就已经全面了解环境及其正确的标签。强化学习则完全不同,我们一开始对环境几乎是完全未知的,只有不断地去了解环境,通过从环境中得到回报(标签)来学习。
其实,监督学习与强化学习之间存在完全不同的学习环境和方法、其适用的场景也不太一致。你会明显感觉到强化学习更类似于人在探索未知时的学习方式。再举一个例子,当一个小孩在学习是非观时,有两种方式。
-
如果按照监督学习的方式,类似于大人会给小孩说,这样做是对的,那样做是错误的。然后,小孩就能知道怎样做是对的,怎样是错误的了。这个过程并不存在奖励机制,无法从环境中获得回报。
-
如果按照强化学习的方式,类似于大人什么都不告诉小孩,当小孩说脏话时就会挨打(负奖励),小孩做正确的事情时就给一颗糖吃(正奖励)。最后,小孩也就建立起是非观念了。为了得到更多的糖吃,小孩就会尽量避免做错误的事情。
84.5. 强化学习算法分类#
与监督和非监督学习方法相似,强化学习也包含有多种不同的算法。而这些算法可以通过多个维度进行细分,如下表所示:
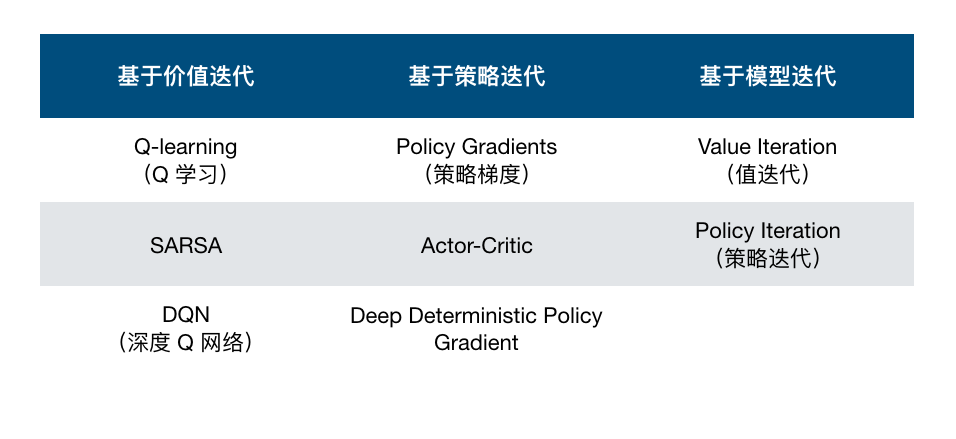
84.6. 强化学习应用#
这里,我们介绍几个强化学习的实际应用。其中名气最大的应该就是 AlphaGo 围棋程序了。AlphaGo 是于 2014 年开始由 Google DeepMind 开发的围棋程序,人类选手几乎无法与之匹敌了。

根据 DeepMind 发布的论文介绍,AlphaGo 使用到了强化学习中的蒙特卡洛树搜索(Monte Carlo tree search),并借助估值网络深度神经网络(Value network)与走棋网络深度神经网络(Policy network)完成落子。
除此之外,像初创公司 COVARIANT.AI 开始使用强化学习来打造更加强大的工业机器人,摩根大通使用强化学习建立新的证券交易系统,以及 Facebook 使用强化学习训练可以参与谈判的聊天机器人等。
所以,欢迎跟随本次课程的内容学习并掌握强化学习相关的入门算法和基础知识点。
84.7. 课外内容推荐#
如果你第一次接触强化学习,后面的实验可能会较为困难。强化学习中的很多概念都非常抽象,理解不太容易。我们推荐的学习方法是「反复琢磨」,反复学习能加深理解,让你对强化学习更加了解。
当然,如果你的学习和工作中几乎不可能接触到强化学习,我们认为也没必要太深入。强化学习目前也是前沿学科,偏向于学术研究领域。当然,如果你想对强化学习有更加深入的认识,非常推荐学习完本章内容后,观看 Google DeepMind 研究员 David Silver 的系列强化学习课程:
○ 欢迎分享本文链接到你的社交账号、博客、论坛等。更多的外链会增加搜索引擎对本站收录的权重,从而让更多人看到这些内容。