
70. 循环神经网络构建#
70.1. 介绍#
前面的实验中,我们了解并学习了循环神经网络(Recurrent Neural Networks,简称 RNN)。循环神经网络被广泛运用在自然语言处理,语音识别等领域,其具备的「记忆」能力在序列模型处理上有巨大的优势。本节课我们将学习如何使用深度学习框架来构建循环神经网络并完成训练。
70.2. 知识点#
IMDB 数据集
词嵌入
简单循环神经网络
LSTM 循环神经网络
前面,我们介绍了循环神经网络的概念。并通过图文举例来了解了简单的循环神经网络,以及常用的
LSTM 网络结构,GRU 网络结构等。对于像 LSTM
网络结构如果使用低阶 API
实现还是较为复杂,所以本次实验主要是利用
tf.keras
等高阶 API 来完成。
除此之外,搭建循环神经网络不可避免会接触到一些自然语言相关的名词和知识点,大家需要多查阅资料来帮助理解。后面的课程内容中,也会涉及到对自然语言处理更深入的学习。
70.3. IMDB 数据集#
和之前接触过的众多数据集一样,IMDB 数据集是一个非常流行的基准数据集,很多论文用它来测试算法的性能。IMDB 数据来源于著名的互联网电影数据库 IMDB.COM。

该数据集共有 50000 条评论数据,并被打上了积极(1)或消极(0)的标签。数据集中的每一条评论都经过预处理,并编码为词索引(整数)的序列表示。词索引的意思是,将词按数据集中出现的频率进行索引,例如整数 3 编码了数据中第三个最频繁的词。一般情况下,IMDB 数据集会被划分为训练集和测试集各占一半,斯坦福研究人员在 2011 年发布该数据集时,得到的预测准确率为 88.89%。
import numpy as np
import tensorflow as tf
# 加载数据, num_words 表示只考虑最常用的 n 个词语,代表本次所用词汇表大小
MAX_DICT = 1000
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.imdb.load_data(
num_words=MAX_DICT
)
X_train.shape, y_train.shape, X_test.shape, y_test.shape
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb.npz
17464789/17464789 [==============================] - 1s 0us/step
((25000,), (25000,), (25000,), (25000,))
可以看到,训练集和测试集各有 25000 条数据。下面输出
X_train[0]
查看第一条评论:
np.array(X_train[0]) # 直接运行
array([ 1, 14, 22, 16, 43, 530, 973, 2, 2, 65, 458, 2, 66,
2, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670,
2, 9, 35, 480, 284, 5, 150, 4, 172, 112, 167, 2, 336,
385, 39, 4, 172, 2, 2, 17, 546, 38, 13, 447, 4, 192,
50, 16, 6, 147, 2, 19, 14, 22, 4, 2, 2, 469, 4,
22, 71, 87, 12, 16, 43, 530, 38, 76, 15, 13, 2, 4,
22, 17, 515, 17, 12, 16, 626, 18, 2, 5, 62, 386, 12,
8, 316, 8, 106, 5, 4, 2, 2, 16, 480, 66, 2, 33,
4, 130, 12, 16, 38, 619, 5, 25, 124, 51, 36, 135, 48,
25, 2, 33, 6, 22, 12, 215, 28, 77, 52, 5, 14, 407,
16, 82, 2, 8, 4, 107, 117, 2, 15, 256, 4, 2, 7,
2, 5, 723, 36, 71, 43, 530, 476, 26, 400, 317, 46, 7,
4, 2, 2, 13, 104, 88, 4, 381, 15, 297, 98, 32, 2,
56, 26, 141, 6, 194, 2, 18, 4, 226, 22, 21, 134, 476,
26, 480, 5, 144, 30, 2, 18, 51, 36, 28, 224, 92, 25,
104, 4, 226, 65, 16, 38, 2, 88, 12, 16, 283, 5, 16,
2, 113, 103, 32, 15, 16, 2, 19, 178, 32])
可以看到,输出的为词索引。那么,如果想看到原评论内容就需要通过索引从字典中找到原单词,可以通过如下代码完成:
index = tf.keras.datasets.imdb.get_word_index() # 获取词索引表
reverse_index = dict([(value, key) for (key, value) in index.items()])
comment = " ".join([reverse_index.get(i - 3, "#") for i in X_train[0]]) # 还原第 1 条评论
comment
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json
1641221/1641221 [==============================] - 1s 0us/step
"# this film was just brilliant casting # # story direction # really # the part they played and you could just imagine being there robert # is an amazing actor and now the same being director # father came from the same # # as myself so i loved the fact there was a real # with this film the # # throughout the film were great it was just brilliant so much that i # the film as soon as it was released for # and would recommend it to everyone to watch and the # # was amazing really # at the end it was so sad and you know what they say if you # at a film it must have been good and this definitely was also # to the two little # that played the # of # and paul they were just brilliant children are often left out of the # # i think because the stars that play them all # up are such a big # for the whole film but these children are amazing and should be # for what they have done don't you think the whole story was so # because it was true and was # life after all that was # with us all"
最开始加载数据集时,我们设定了
num_words=1000,即代表数据集只包含 1000
各常用词的字典。所以上面的输出语句中,部分用 #
代替的词即不包含在这 1000 各常用词之中。
如果你输出多条评论后,你会发现每条评论的长度大小不一。但是神经网络输入时,我们必须保证每一条数据的形状是一致的,所以这里需要对数据进行预处理。
这里使用
tf.keras.preprocessing.sequence.pad_sequences()
🔗
进行处理,通过指定最大长度
maxlen
达到裁切向量的目的。同时,如果原句子长度不足,将会在头部通过
0 填充。
MAX_LEN = 200 # 设定句子最大长度
X_train = tf.keras.preprocessing.sequence.pad_sequences(X_train, MAX_LEN)
X_test = tf.keras.preprocessing.sequence.pad_sequences(X_test, MAX_LEN)
X_train.shape, X_test.shape
((25000, 200), (25000, 200))
此时,你可以看到每一条句子都被强制处理成规定长度。
我们都知道,机器无法像人类一样去理解自然语言,所以需要将语句转换为张量。上面的预处理过程中,每一个单词都已经被「字典」转换成了数字,句子也已经以词索引的形式表示,那是不是就可以输入到神经网络中了呢?
答案当然是肯定的。但根据经验,这样简单的字典转换往往效果并不好。所以一般会引入其它手段对词索引进一步处理。
70.4. 词嵌入#
词嵌入,英文叫 Word Embedding,这是一种十分常用的词索引特征化手段。
关于 Embedding,这里举一个简单的例子用来理解。例如单词 apple 对应的词索引为 100。通过 Embedding 转化后,100 就可以变成一个指定大小的向量,比如转化为 \([1, 2, 1]\)。其中,1 表示 apple 是个很讨人喜欢的东西,2 表示 apple 是个水果,最后的 1 表示 apple 是有益身体健康的,这就是一个特征化的过程。
字典只能单纯将词处理成数值,但 Embedding 却可以让词与词直接产生联系。例如 orange 就可能因为和 apple 具备同样的水果特性,从而在空间上离得更近一些。如下举例,Embedding 能自由地将语义上相似的项归到一起,并将相异项分开。例如国家和首都,男性和女性。

关于词嵌入,后续实验会有进一步讲解。Keras 中的嵌入层
tf.keras.layers.Embedding
🔗
可以帮助我们快速完成 Embedding 的过程。
tf.keras.layers.Embedding(input_dim, output_dim, embeddings_initializer='uniform', embeddings_regularizer=None, activity_regularizer=None, embeddings_constraint=None, mask_zero=False, input_length=None)
- input_dim:int > 0,词汇表大小。
- output_dim:int >= 0,词向量的维度。
- input_length:输入序列的长度,当它是固定的时候。如果你需要连接 Flatten 和 Dense 层,则这个参数是必须的。
有了 Embedding 结构,我们就可以搭建一个简单的全连接网络来完成评论情绪分类了。
model = tf.keras.Sequential()
model.add(tf.keras.layers.Embedding(MAX_DICT, 16, input_length=MAX_LEN))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(1, activation="sigmoid"))
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) (None, 200, 16) 16000
flatten (Flatten) (None, 3200) 0
dense (Dense) (None, 1) 3201
=================================================================
Total params: 19201 (75.00 KB)
Trainable params: 19201 (75.00 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
上面的模型中,input_dim=
传入先前词汇表设定值。而后面连接 Flatten
层时,根据文档需要指定
input_length=,也就是输入序列被强制裁剪后的长度。
模型在训练时需要一个损失函数和一个优化器。由于这是一个二元分类问题且模型会输出一个概率(应用
S 型激活函数的单个单元层),因此我们将使用
binary_crossentropy
二分类交叉熵损失函数。
model.compile(optimizer="Adam", loss="binary_crossentropy", metrics=["accuracy"])
最后,完成迭代训练和评估。
EPOCHS = 1
BATCH_SIZE = 64
model.fit(X_train, y_train, BATCH_SIZE, EPOCHS, validation_data=(X_test, y_test))
391/391 [==============================] - 1s 1ms/step - loss: 0.5799 - accuracy: 0.6917 - val_loss: 0.3916 - val_accuracy: 0.8359
<keras.src.callbacks.History at 0x28f2a56c0>
70.5. 简单循环神经网络#
简单循环神经网络也就是全连接的
RNN,其输出将被反馈到输入中。TensorFlow 中可以直接调用
tf.keras.layers.SimpleRNN
🔗
来实现。
tf.keras.layers.SimpleRNN(units, activation='tanh', use_bias=True, kernel_initializer='glorot_uniform', recurrent_initializer='orthogonal', bias_initializer='zeros', kernel_regularizer=None, recurrent_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, recurrent_constraint=None, bias_constraint=None, dropout=0.0, recurrent_dropout=0.0, return_sequences=False, return_state=False, go_backwards=False, stateful=False, unroll=False)
- units: 正整数,输出空间的维度。
- activation: 要使用的激活函数。如果传入 None,则使用线性激活。
- use_bias: 布尔值,该层是否使用偏置项量。
- dropout: 在 0 和 1 之间的浮点数。
- return_sequences: 布尔值。是返回输出序列中的最后一个输出,还是全部序列。
这里解释一下参数
dropout
的含义。实际上,Dropout
是深度学习中经常会接触到的概念,其经常以
tf.keras.layers.Dropout
🔗
这样的网络层出现。Dropout
主要的作用是防止过拟合,实现原理是以一定概率(Dropout
参数值)断开神经元之间的连接。除此之外,关于
return_sequences
可以阅读:Keras 中 LSTM 层两个重要参数理解。
下面开始使用 Keras 构建顺序模型结构,该循环神经网络分为 3 层,分别是 Embedding,SimpleRNN,以及用于输出的 Dense 全连接层。
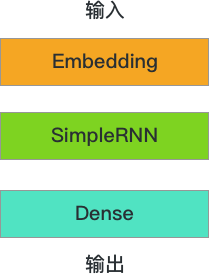
代码如下:
model_RNN = tf.keras.Sequential()
model_RNN.add(tf.keras.layers.Embedding(MAX_DICT, 32))
# dropout 是层与层之前的 dropout 数值,recurrent_dropout 是上个时序与这个时序的 dropout 值
model_RNN.add(tf.keras.layers.SimpleRNN(units=32, dropout=0.2, recurrent_dropout=0.2))
model_RNN.add(tf.keras.layers.Dense(1, activation="sigmoid"))
model_RNN.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_1 (Embedding) (None, None, 32) 32000
simple_rnn (SimpleRNN) (None, 32) 2080
dense_1 (Dense) (None, 1) 33
=================================================================
Total params: 34113 (133.25 KB)
Trainable params: 34113 (133.25 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
model_RNN.suammry()
可以帮我们清晰地看出模型结构,模型总共要学的参数数量较大。接下来,我们对模型进行编译和训练,并最终输出模型在测试集上的评估情况。
model_RNN.compile(optimizer="Adam", loss="binary_crossentropy", metrics=["accuracy"])
model_RNN.fit(X_train, y_train, BATCH_SIZE, EPOCHS, validation_data=(X_test, y_test))
391/391 [==============================] - 12s 31ms/step - loss: 0.7037 - accuracy: 0.5177 - val_loss: 0.6864 - val_accuracy: 0.5347
<keras.src.callbacks.History at 0x28bc3d300>
关于模型准确度的分析,详见实验后半部分。
70.6. LSTM 循环神经网络#
下面,我们把上面的 SimpleRNN 结构更换为 LSTM
结构,TensorFlow 中可以直接调用
tf.keras.layers.LSTM
🔗
来实现。API 参数上与 SimpleRNN 近乎相同,这里就不再赘述了。
model_LSTM = tf.keras.Sequential()
model_LSTM.add(tf.keras.layers.Embedding(MAX_DICT, 32))
model_LSTM.add(tf.keras.layers.LSTM(units=32, dropout=0.2, recurrent_dropout=0.2))
model_LSTM.add(tf.keras.layers.Dense(1, activation="sigmoid"))
model_LSTM.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_2 (Embedding) (None, None, 32) 32000
lstm (LSTM) (None, 32) 8320
dense_2 (Dense) (None, 1) 33
=================================================================
Total params: 40353 (157.63 KB)
Trainable params: 40353 (157.63 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
从
model_LSTM.summary()
的输出中我们看到,LSTM 比起简单 RNN
会多学到一些参数,但这些参数帮助我们规避了梯度消失等致命性问题。我们保持其他几层神经网络不变,LSTM
的两个 dropout 与 SimpleRNN 的两个 dropout 值一致。
接下来,开始训练 LSTM 网络。由于参数变多了,整个训练时间会明显比之前的久一些。
model_LSTM.compile(optimizer="Adam", loss="binary_crossentropy", metrics=["accuracy"])
model_LSTM.fit(X_train, y_train, BATCH_SIZE, EPOCHS, validation_data=(X_test, y_test))
391/391 [==============================] - 39s 98ms/step - loss: 0.4891 - accuracy: 0.7540 - val_loss: 0.3546 - val_accuracy: 0.8464
<keras.src.callbacks.History at 0x28832dbd0>
观察得到,LSTM 在测试集上的准确率会比 SimpleRNN 提高一些。LSTM 做为一个循环神经网络的模块,设计非常巧妙,通过遗忘门和输入门对记忆单元不断更新,消除了循环神经网络训练时梯度消失的致命问题,并由此得到了广泛运用。
最终,我们简单改动代码把之前的 LSTM 层替换为 GRU 层。GRU 结构相对于 LSTM 学习的参数会少一些,但是准确率不一定会更好。
model_GRU = tf.keras.Sequential()
model_GRU.add(tf.keras.layers.Embedding(MAX_DICT, 32))
model_GRU.add(tf.keras.layers.GRU(units=32, dropout=0.2, recurrent_dropout=0.2))
model_GRU.add(tf.keras.layers.Dense(1, activation="sigmoid"))
model_GRU.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding_3 (Embedding) (None, None, 32) 32000
gru (GRU) (None, 32) 6336
dense_3 (Dense) (None, 1) 33
=================================================================
Total params: 38369 (149.88 KB)
Trainable params: 38369 (149.88 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
model_GRU.compile(optimizer="Adam", loss="binary_crossentropy", metrics=["accuracy"])
model_GRU.fit(X_train, y_train, BATCH_SIZE, EPOCHS, validation_data=(X_test, y_test))
391/391 [==============================] - 34s 84ms/step - loss: 0.5066 - accuracy: 0.7357 - val_loss: 0.3934 - val_accuracy: 0.8260
<keras.src.callbacks.History at 0x28d5b3a90>
最后,我们来讨论一下本次实验测试集评估准确度的问题。
上面我们分别建立了全连接网络,SimpleRNN,LSTM 和 GRU 四种模型。你可能会发现循环神经网络在很多适合竟然没有全连接表现的好,特别是 SimpleRNN。不是说循环神经网络很擅长自然语言处理吗?实际上,由于循环神经网络涉及大量的参数,其在训练可能会有一些小的技巧。例如,知乎上有一个关于 你在训练 RNN 的时候有哪些特殊的 Trick 的讨论。这需要你对网络有深入了解和应用经验后才能够熟悉。
另外,Francois Chollet(Keras 的创始人)曾经说过,LSTM 等循环神经网络对情绪分析问题的帮助较小。虽然这种说法 有待商榷,但是在 IMDB 数据集上,LSTM 的表现似乎的确不尽如人意。这应该也是测试集准确度较低的一个原因。
最后,实验提供一个解决思路来提升 IMDB 分类准确度。该方案使用了 TFIDF + 逻辑回归。TFIDF 是一种特征提取方法,最终取得了测试集 89% 的准确度。有兴趣可以 通过 GitHub 查看源代码。
70.7. 总结#
本次实验,我们重点学习了如何使用
tf.keras
提供的高阶 API 来建立循环神经网络模型。tf.keras
提供了常用的 SimpleRNN,LSTM,GRU
等循环神经网络结构,是通常情况下的首选方案。虽然循环神经网络在一些特定的问题上并没有明显的优势,但是其作用不可小觑。后面,随着我们对自然语言处理学习的深入,你会陆续看到一些循环神经网络非常好的示例。
○ 欢迎分享本文链接到你的社交账号、博客、论坛等。更多的外链会增加搜索引擎对本站收录的权重,从而让更多人看到这些内容。