
82. 深度学习云端服务实践#
82.1. 介绍#
本次实验中,我们将介绍深度学习的工程应用中常涉及到的云计算服务。你需要了解并尝试应用这些技术去提高深度学习开发应用的效率。
82.2. 知识点#
深度学习计算平台
深度学习解决方案
深度学习的工程应用阶段,还有一块不得不介绍的内容:云服务。多年以前,每个互联网公司都有自己的机房和服务器。随着 PaaS(平台即服务,英语:Platform As A Service)和 SaaS(软件即服务,英语:Software As A Service)的兴起,云计算服务逐渐被接受和使用。
目前来讲,提供深度学习和机器学习相关的云服务还算比较多。其中,个人用户可用且较大的厂商主要有:Google Cloud,AWS,Microsoft Azure,阿里云,百度云 等。
虽然 Google Cloud 在人工智能方面拥有业界领先的技术,但由于众所周知的原因,其无法在国内正常访问。所以,本次实验我们主要选取国外的 AWS,以及国内的阿里云,百度云提供的各项与深度学习相关的云服务进行介绍。
特别说明的是,本次实验中介绍和推荐的云服务产品与课程制作团队之间并无商业利益关系,均是团队成员经常使用的工具或服务。
82.3. 国外 AWS#

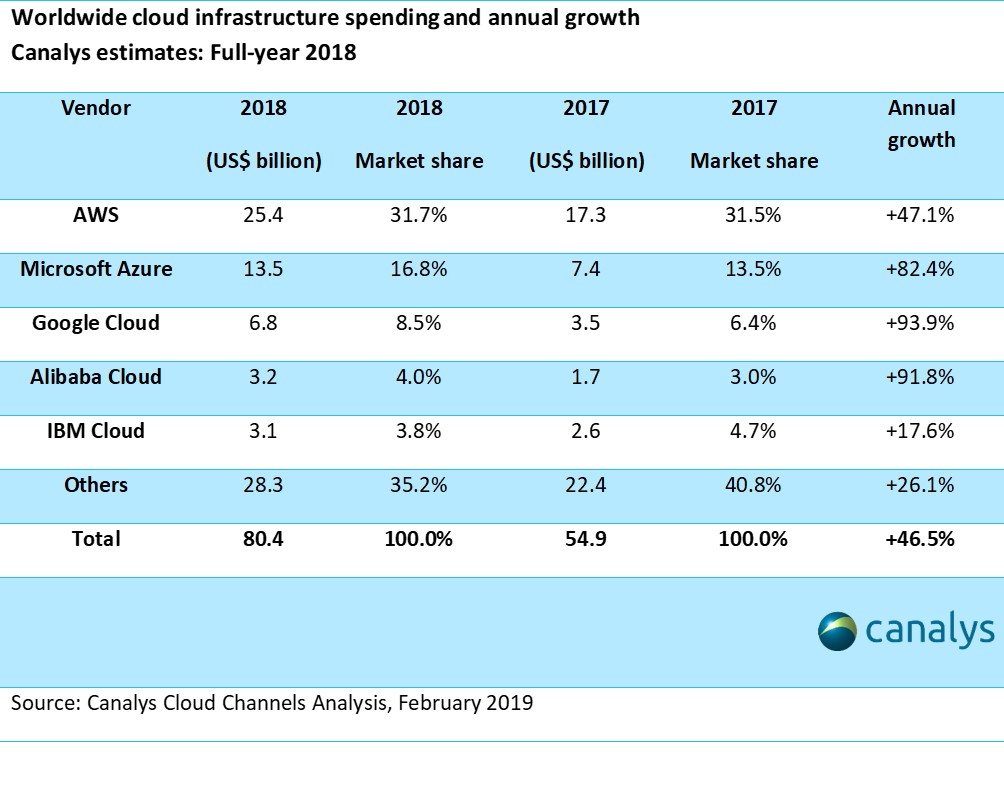
AWS 是亚马逊云计算服务的缩写,根据 canalys 的数据 显示,AWS 是近些年全球市场份额最大的云计算服务商。下表统计了全球云计算服务商 2017,2018 年全年市场份额和市场增长情况,其中 AWS 稳定占据了 30% 左右的市场份额并保持稳定增长。
目前对于深度学习而言,所有的云服务厂商主要是提供两大类产品,我们将其归纳为:工具和服务。其中,工具指的是可以帮助开发者完成深度学习的一系列产品,包括云主机,云 GPU,云端 Jupyter Notebook 等。而服务则指的是现有的 API,大多数服务商自己在深度学习方法有较好的人员和技术积累,直接提供了可用于计算机视觉或者自然语言处理相关的云端接口。

当然,对于工具而言,要求开发者本身掌握深度学习相关的技术。而对于服务来说,开发者只需要了解如何调用 API 接口即可,可以完全不具备深度学习技能。
82.3.1. AWS Deep Learning AMI#
AMI 是 AWS 提供的环境镜像缩写,AWS 专门为深度学习提供了一系列预配置的环境方便快速构建模型。目前,AWS Deep Learning AMI 只提供 Amazon Linux 和 Ubuntu 操作系统的环境,并预安装了 TensorFlow、PyTorch、Apache MXNet、Chainer、Microsoft Cognitive Toolkit、Gluon、Horovod 和 Keras 等几乎全部常见的深度学习框架。
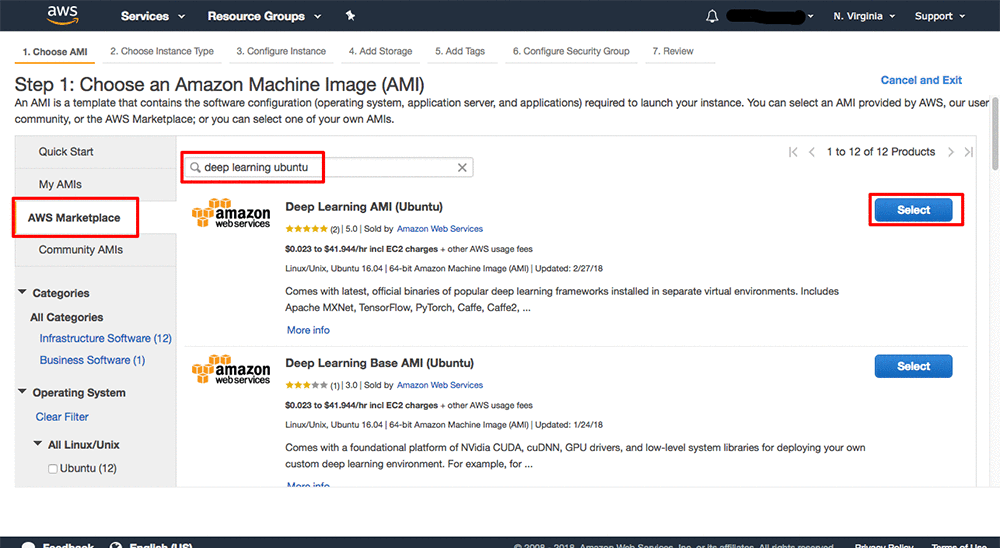
简单来讲,你可以一键启动一台已经配置好深度学习环境的云主机,这种即开即用的体验是极为方便的。关于 AWS Deep Learning AMI 的详细使用步骤,可以阅读 Get Started with Deep Learning Using the AWS Deep Learning AMI。
82.3.2. Amazon SageMaker#
AWS Deep Learning AMI 默认只支持 AWS EC2 云主机,其运行的操作系统一般为 Ubuntu 服务器版本,即没有图形界面。如果你对 Linux 不熟悉,那么使用起来恐怕会比较难受。Amazon SageMaker 则是一项面向深度学习更有针对性的云计算服务,其能帮助开发者快速构建、训练和部署机器学习模型。
简单来讲,Amazon SageMaker 是一项完全托管的服务,它覆盖了整个机器学习工作流程,包括:标记和准备数据、选择算法、训练模型、调整和优化部署、以及模型推理。
最方便的是,Amazon SageMaker 默认使用 Jupyter Notebook,这应该是机器学习和数据科学家最熟悉的 IDE 了。关于 Amazon SageMaker 的详细介绍和使用说明,可以阅读 相关链接。
上面我们介绍了 AWS 针对机器/深度学习推出了两项非常方便的云计算服务,这两项服务也是课程制作团队经常使用的服务,简单易用高效方便。但值得注意的时,当你选择 GPU 云主机实例进行运算时,一定要注意使用结束后删除 Amazon SageMaker 实例,否则可能导致高昂的费用产生。
82.3.3. AWS AI Service#
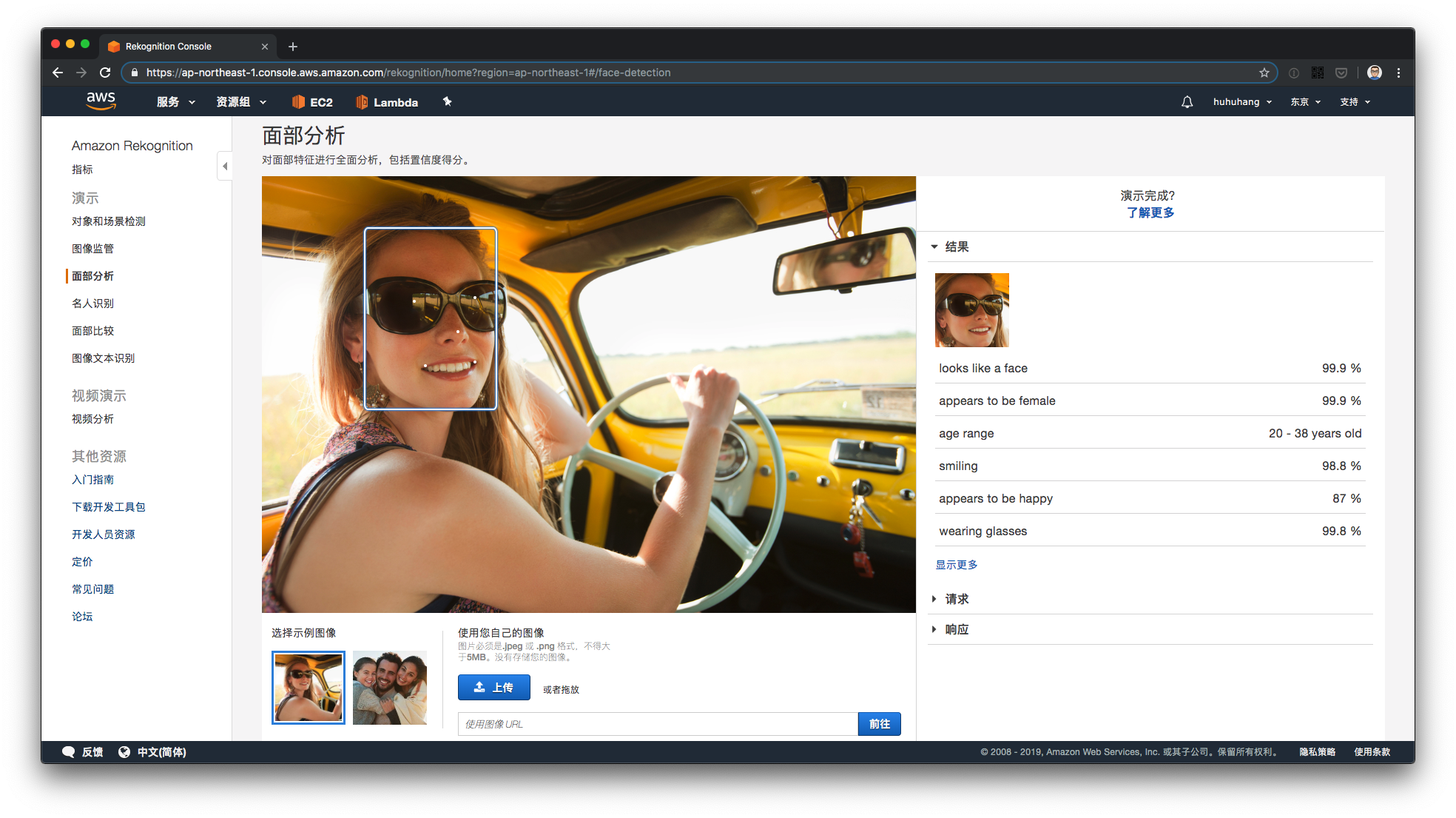
除了上面针对深度学习开发人员提供的工具,AWS 同样提供了许多现成的 API 供直接调用。例如,Amazon Comprehend 是一项可以用于发现文本中的见解和关系的自然语言处理服务。Amazon Lex 则可以用于构建语音和文本聊天机器人。Amazon Rekognition 可以用来分析图像或视频内容,包括人脸识别、目标检测等,你可以通过 此链接 进行体验。
Note
新注册的 AWS 账户可以获得以上服务一定的免费体验额度,详情需了解 AWS 免费套餐 计划。
82.4. 国内云服务#
AWS 虽然是全球最受欢迎的云服务,但在很多方面国内的阿里云、腾讯云、百度云等似乎更接地气。举例来讲,AWS 提供了通用的文本检测和识别服务,而阿里云却有针对性地提供了增值税发票内容识别,出租车机打发票识别,身份证内容识别等更细分的识别服务。
在基础的技术层面,国内云服务也提供 GPU 云主机,预配置镜像等,并且在价格上和 AWS 等区别不大,所以这里不再赘述。有兴趣可以千万相应云服务商官网自行了解。
而在服务层面,国内云服务商提供的 API 接口更加丰富,价格更为便宜,调用更为方便。接下来,我们以百度云为例进行介绍。选择百度云的原因在于,国内的阿里云、腾讯云、百度云提供的产品比较相似,大多数服务也很相似。相比而言,百度云提供较多的免费额度,SDK 调用也更为方便,所以本次线上实验以百度云作为示例。
百度云 官网列举了其提供的产品和服务,分为应用和平台两个类别,实际上也就是其对应的 SaaS 和 PaaS 产品。平台方面,主要是以算力作为支撑,像其中的 BML 实际上是类似于 Amazon SageMaker 的线上 Jupyter Notebook 模型训练服务。而应用方面则类似于 AWS AI Service,只不过提供的接口更加丰富。

你可以注册一个免费账户来使用百度云提供的一系列接口。接下来,我们就通过百度云提供的 API 来尝试完成一些操作。在这之前,我们安装百度云提供的 Python 开发 SDK。
pip install baidu-aip # 安装百度云 SDK
接下来,你需要登录并选择自己需要的服务,获取 API KEY。例如,我们选择 自然语音服务,并创建一个应用。勾选你需要调用的接口类型,最终就可以生成 API KEY 了。
接下来,我们调用 SDK 并填入申请到的密钥。
# 注册应用后会自动生成下方 3 个 KEY 信息
APP_ID = '16XX0141'
API_KEY = '0HUECBnXXXXo2EpiI8kqP5I'
SECRET_KEY = 'DdomRyxgwXXXXSlo1mroZu2YLN8jN'
接下来,我们先演示几个自然语音处理相关的应用,你也可以阅读官方 技术文档。首先,建立一个客户端链接:
from aip import AipNlp
client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
client
目前,百度云提供以下自然语言处理相关的应用接口:
| 接口名称 | 接口能力简要描述 |
|---|---|
| 词法分析 | 分词、词性标注、专名识别 |
| 依存句法分析 | 自动分析文本中的依存句法结构信息 |
| 词向量表示 | 查询词汇的词向量,实现文本的可计算 |
| DNN 语言模型 | 判断一句话是否符合语言表达习惯,输出分词结果并给出每个词在句子中的概率值 |
| 词义相似度 | 计算两个给定词语的语义相似度 |
| 短文本相似度 | 判断两个文本的相似度得分 |
| 评论观点抽取 | 提取一个句子观点评论的情感属性 |
| 情感倾向分析 | 对包含主观观点信息的文本进行情感极性类别(积极、消极、中性)的判断,并给出相应的置信度 |
| 中文分词 | 切分出连续文本中的基本词汇序列(已合并到词法分析接口) |
| 词性标注 | 为自然语言文本中的每个词汇赋予词性(已合并到词法分析接口) |
| 新闻摘要 | 自动抽取新闻文本中的关键信息,进而生成指定长度的新闻摘要 |
情感倾向分析是非常常见的一类 NLP 应用了,相应的 API 包含主观观点信息的文本进行情感极性类别(积极、消极、中性)的判断,并给出相应的置信度。
text = "动手实战人工智能是一门不错的课程"
client.sentimentClassify(text) # 调用情感倾向分析
返回数据中,sentiment
表示情感极性分类结果,confidence
表示分类的置信度,positive_prob
表示属于积极类别的概率,negative_prob
表示属于消极类别的概率。
此外,我们来试一试文本纠错的 API,例如:
text = "动手实战人公智能是一门不错得课程"
data = client.ecnet(text)
print(f"纠错后:{data['item']['correct_query']}")
data
可以看到,对于常用词的纠错能力还是不错的,正确纠正了错别字。
由于 NLP 相关的接口较多,这里就不再一一举例,你可以根据自己的想法和兴趣参考官方 技术文档。这里我们就不得不提到国内云服务的一个很大的优势,那就是官方文档都是中文书写,这对于开发者使用更加方便。
接下来,我们测试一些计算机视觉相关的服务,目前百度提供的图像识别相关的接口有:
| 接口名称 | 接口能力简要描述 |
|---|---|
| 图像主体检测 | 识别图像中的主体具体坐标位置。 |
| 通用物体和场景识别高级版 | 识别图片中的场景及物体标签,支持 10w+ 标签类型。 |
| 菜品识别 | 检测用户上传的菜品图片,返回具体的菜名、卡路里、置信度信息。 |
| 自定义菜品识别 | 入库自定义的单菜品图,实现上传多菜品图的精准识别,返回具体的菜名、位置、置信度信息 |
| LOGO 商标识别 | 识别图片中包含的商品 LOGO 信息,返回 LOGO 品牌名称、在图片中的位置、置信度。 |
| 动物识别 | 检测用户上传的动物图片,返回动物名称、置信度信息。 |
| 植物识别 | 检测用户上传的植物图片,返回植物名称、置信度信息。 |
| 花卉识别 | 检测用户上传的花卉图片,返回花卉名称、置信度信息。 |
| 果蔬食材识别 | 检测用户上传的果蔬类图片,返回果蔬名称、置信度信息。 |
| 地标识别 | 检测用户上传的地标图片,返回地标名称。 |
| 红酒识别 | 识别图像中的红酒标签,返回红酒名称、国家、产区、酒庄、类型、糖分、葡萄品种、酒品描述等信息。 |
| 货币识别 | 识别图像中的货币类型,返回货币名称、代码、面值、年份信息,可识别百余种国内外常见货币。 |
实验测试一下菜品识别接口。根据其文档介绍,菜品识别可以输出菜品名称、卡路里信息和置信度。
首先导入一张示例图片:
import requests
from PIL import Image
from io import BytesIO
# 请求网络图片
response = requests.get(
'https://cdn.aibydoing.com/aibydoing/files/salad.jpeg')
image_raw = response.content
image = Image.open(BytesIO(image_raw)) # 读取为 PIL 对象可视化
image
图像识别 API 只能传入图像数据,不接受上面 PIL
对象,所以下方输入为
image_raw
变量。
from aip import AipImageClassify
client = AipImageClassify(APP_ID, API_KEY, SECRET_KEY)
client.dishDetect(image_raw)
API 会返回置信度前 5 的预测类别。如果对应的菜名存在百度百科词条,也会一并返回。同样,这里就不再逐一举例,你可以根据自己的兴趣自行尝试其他的图像识别接口。
82.5. 云服务选择#
至此,我们已经对国内外常用的几个云服务进行了介绍。对于深度学习云服务涉及到的平台和接口,我们在此提供一些云服务选择上的建议,希望对你有所帮助。
首先,如果是选择训练平台,例如云主机或者支持深度学习训练相关的服务,首先考虑 AWS 等国外服务。原因在于,深度学习一定会涉及到很多相关的资源和应用,而像一些工具,先进的预训练模型往往都托管在外网服务器中,使用 AWS 等国外服务商提供的主机和服务能有效改善网络质量。下载速度快,使用方便,能有效避免一些资源在国内无法正常访问的情况。
其次,像 AWS,Google Cloud 在这方面做得的确很好。比如 Amazon SageMaker,虽然国内有很多模仿者,但却很难在体验上超越。
另一方面,如果你选择现有的 API 接口服务,优先考虑国内的云服务商。原因在于,国内服务商提供了很多更细分专业的接口,调用方便价格便宜。与上面选择平台正好相反,你所开发的服务大多是面向国内用户的,自然选择国内服务商会拥有更快的国内连接速度。
最后,我们再讨论一个话题,那就是:既然有现成的云服务,为什么还要自己学习相关技术呢?
学习完本实验,我相信很多学员都有这样的疑问,既然云服务商提供的现成 API 接口很不错,那么自己学习深度学习的意义何在?的确,对于云服务商而言,他们有强大的技术团队,算力和数据集支撑,一般商用的服务都不错。很多时候,你自己训练的模型还不如直接调接口好用。但是,这些只是云服务商的优势。
人的创造力是无可替代的,云服务商推出的服务都是有商业选择的,大多都是通用能盈利的服务。但这些服务不可能覆盖所有的需求,面对更加细分的场景,只能由懂技术的工程师去解决。
82.6. 总结#
本次实验中,我们介绍了与深度学习相关的常用云计算厂商和它们提供的服务。人工智能的浪潮下,更大规模的云计算应用,无服务器开发等已经成为了新趋势,我们需要了解并使用这些服务和技术。当然,由于这些技术的更新迭代速度快,需要你及时关注并尝试应用。
○ 欢迎分享本文链接到你的社交账号、博客、论坛等。更多的外链会增加搜索引擎对本站收录的权重,从而让更多人看到这些内容。