
76. 神经机器翻译和对话系统#
76.1. 介绍#
前面讲解了循环神经网络,并介绍其在自然语言处理中的一些应用,本次实验将会讲解一种循环神经网络的变体,即序列到序列模型,该模型在自然语言处理中的许多任务都得到了广泛的应用,并都达到了良好的效果。
76.2. 知识点#
序列到序列模型
神经机器翻译系统
聊天机器人系统
自然语言处理涉及到的领域很多,例如构建对话系统、推荐系统以及神经机器翻译等。而这些应用往往需要涉及到大量的专业知识,并偏向于研究型而非入门应用型。前面的实验中,我们重点对自然语言处理中的特征提取和文本分类进行了介绍,本次实验将介绍序列到序列模型,并对其在机器翻译和对话系统中的应用进行初步探索。
76.3. 序列到序列模型#
序列到序列模型(Sequence to Sequence)是一种由编码器和解码器组成的模型,简称 seq2seq。该模型最早由 Yoshua Bengio 团队的成员之一 Kyunghyun Cho 于 2014 年 提出 ,其主要解决的是输入不定长序列和输出不定长序列。
下图左三为 Yoshua Bengio 教授,其他三位大佬你认识吗?😏

先来回顾一下前面所学的循环神经网络。在讲解循环神经网络时,我们提到处理序列问题时主要含有以下几种类型,即:
-
1 → N :生成模型,即输入一个向量,输出长度为 N 个序列。
-
N → 1 :判别模型,即输入长度为 N 个序列,输出一个向量。
-
N → N :标准序列模型,即输入长度为 N 个序列,输出长度为 N 个序列。
-
N → M :不定长序列模型,即输入长度为 N 个序列,输出长度为 M 个序列。
而对于标准循环神经网络来说,其只能解决上面所列出的前三种问题类型,即 1 对 N,N 对 1,N 对 N。换句话说,就是如果输入序列和输出序列不相等,则无法使用标准的循环神经网络来建模。为了解决这一问题,Kyunghyun Cho 等人就提出了编码模型和解码模型,如下图所示:
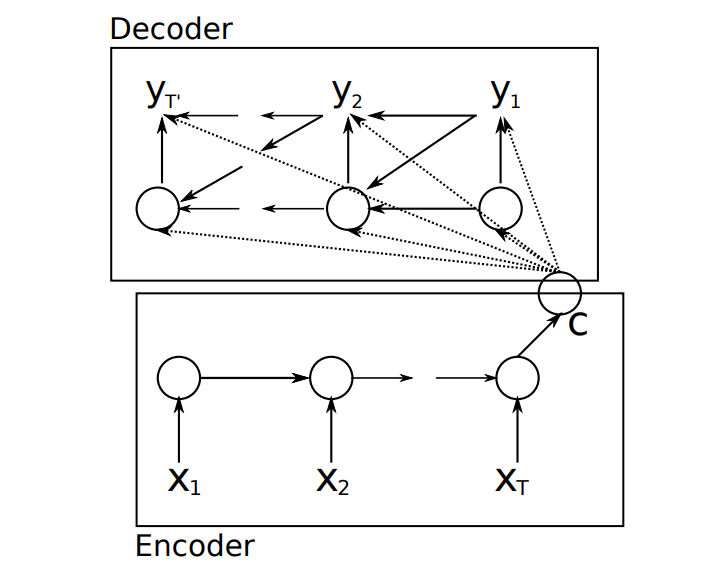
图中,\(X_{i}\) 表示输入序列,\(y_{i}\) 表示输出序列,\(C\) 表示输入序列经过编码后的输出状态。从上图中,我们可以看到,该模型主要由编码器和解码器组成,当我们输入序列 \(X_{i}\) 时,经过循环神经网络编码得到一个状态向量 \(C\) ,而解码器也是一个循环神经网络,其通过编码器得到的状态 \(C\) 来进行解码,从而得到一组输出序列。
为了便于理解,实验举一个简单的例子来说明。假设我们现在要构建一个中译英的机器翻译系统,其要翻译的句子如下:
中文:我有一个苹果
英文:I have a apple
对于机器翻译任务,我们可以建立一个如下图所示的模型。

在上图所示中,要翻译的中文为 6 个字,输入序列的长度为 6。而翻译的结果为 4 个单词,所以输出序列的长度为 4。当我们往 seq2seq 模型输入句子【我有一个苹果】时,模型会通过循环神经网络提取输入句子的特征,然后编码成为一个状态向量。然后将该向量作为解码器的初始状态值,解码器同样也是一个循环神经网络,而循环神经网络每个时刻的输出就是我们想要的翻译结果。
76.4. 神经机器翻译系统#
前文中主要讲解了 seq2seq 模型的原理,现在通过动手实现一个机器翻译系统来加深理解。在讲解机器翻译系统之前,我们先简单介绍一下机器翻译。

机器翻译,顾名思义就是通过计算机将一种语言翻译成为另一种语言。目前主要包括:基于规则的方法,基于统计的方法,以及基于神经网络的方法。
2013 年之前,基于规则和统计模型的机器翻译一直都是主流的方法,如果你感兴趣,可以去阅读宗成庆老师编写的 统计自然语言处理。而在 2013 年之后,基于人工神经网络的机器翻译 (NMT,Neural Mahcine Translation) 逐渐兴起。与之前的统计模型相比,神经网络机器翻译具有译文流畅,准确易理解,翻译速度快等优点,因此基于神经网络的方法逐渐得到许多学者的青睐。
2016 年底,Google 开发并上线了 Google’s Neural Machine Translation,神经网络机器翻译正式登了上舞台。下图即为 Google 翻译的神经网络网络模型。其主要由编码器和解码器组成,且编码器和解码器器都使用 8 层的循环神经网络。
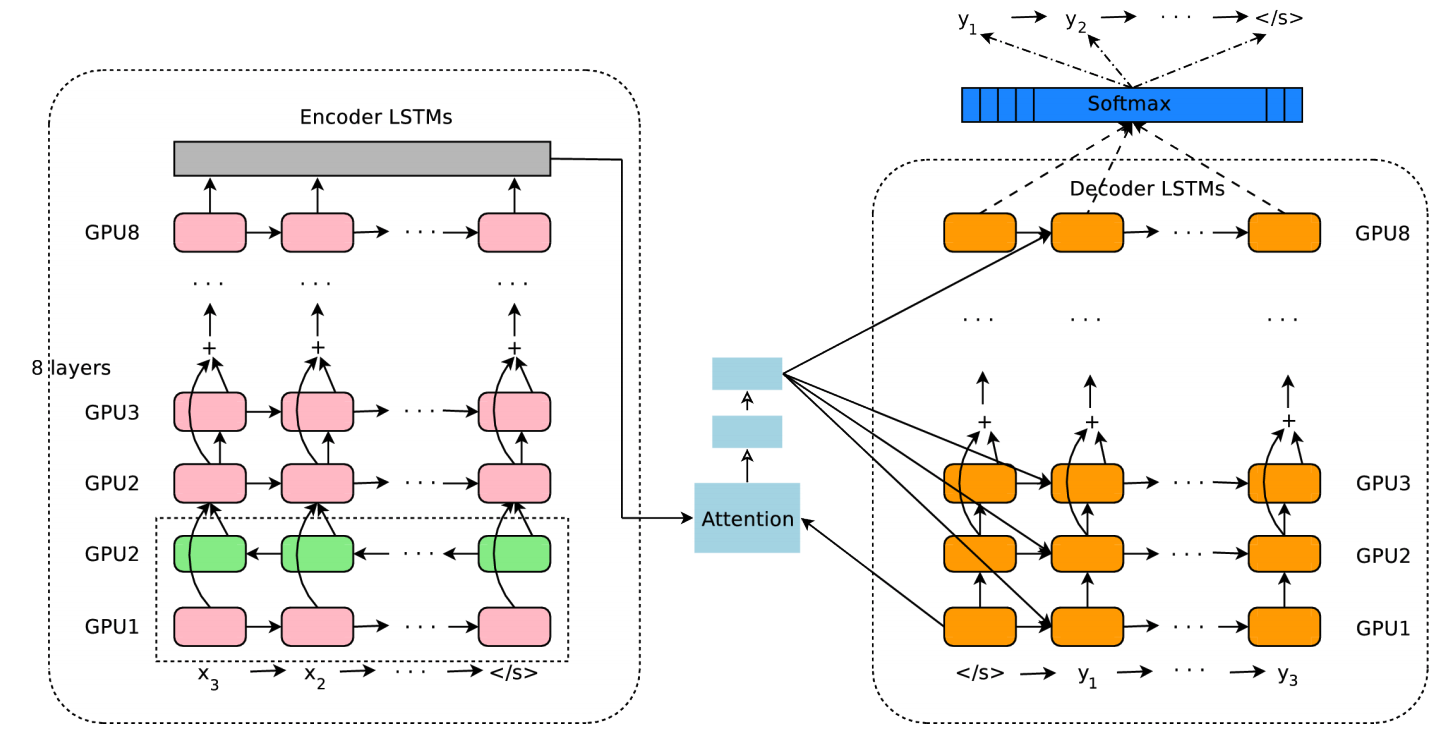
不过,这类商用的神经机器翻译系统都过于复杂。下面,实验动手实现一个小型的机器翻译系统。
76.4.1. 数据构建以及预处理#
神经机器翻译系统的优秀表现依赖于大规模语料数据,本次实验中我们仅用几段简单的中英文语料作为演示。大家重点在于理解神经机器翻译的思想和 seq2seq 方法的原理。
input_texts = [
"我有一个苹果",
"你好吗",
"见到你很高兴",
"我简直不敢相信",
"我知道那种感觉",
"我真的非常后悔",
"我也这样以为",
"这样可以吗",
"这事可能发生在任何人身上",
"我想要一个手机",
]
output_texts = [
"I have a apple",
"How are you",
"Nice to meet you",
"I can not believe it",
"I know the feeling",
"I really regret it",
"I thought so, too",
"Is that OK",
"It can happen to anyone",
"I want a iphone",
]
一般情况下,对于中文句子,都会先对其进行分词后再进行后续的处理。但实验只用到几个句子,所以为了方便,直接将每个字作为一个词来处理。现在对输入句子出现的字进行去重统计。
def count_char(input_texts):
input_characters = set() # 用来存放输入集出现的中文字
for input_text in input_texts: # 遍历输入集的每一个句子
for char in input_text: # 遍历每个句子的每个字
if char not in input_characters:
input_characters.add(char)
return input_characters
input_characters = count_char(input_texts)
input_characters
{'一',
'上',
'不',
'个',
'为',
'也',
'事',
'人',
'以',
'任',
'何',
'你',
'信',
'兴',
'到',
'发',
'可',
'后',
'吗',
'在',
'好',
'常',
'很',
'悔',
'想',
'感',
'我',
'手',
'敢',
'有',
'机',
'果',
'样',
'生',
'的',
'直',
'相',
'真',
'知',
'种',
'简',
'能',
'苹',
'要',
'见',
'觉',
'身',
'这',
'道',
'那',
'非',
'高'}
下面,使用同样的方法对输出的英文句子进行统计。值得注意的是,在每个输出句子中都添加了句子开头标记符号
>
和句子结尾标记符号
<
符号。
def count_word(output_texts):
target_characters = set() # 用来存放输出集出现的单词
target_texts = [] # 存放加了句子开头和结尾标记的句子
for target_text in output_texts: # 遍历输出集的每个句子
target_text = "> " + target_text + " <"
target_texts.append(target_text)
word_list = target_text.split(" ") # 对每个英文句子按空格划分,得到每个单词
for word in word_list: # 遍历每个单词
if word not in target_characters:
target_characters.add(word)
return target_texts, target_characters
target_texts, target_characters = count_word(output_texts)
target_texts, target_characters
(['> I have a apple <',
'> How are you <',
'> Nice to meet you <',
'> I can not believe it <',
'> I know the feeling <',
'> I really regret it <',
'> I thought so, too <',
'> Is that OK <',
'> It can happen to anyone <',
'> I want a iphone <'],
{'<',
'>',
'How',
'I',
'Is',
'It',
'Nice',
'OK',
'a',
'anyone',
'apple',
'are',
'believe',
'can',
'feeling',
'happen',
'have',
'iphone',
'it',
'know',
'meet',
'not',
'really',
'regret',
'so,',
'that',
'the',
'thought',
'to',
'too',
'want',
'you'})
然后,实验通过建立一个字典,将字符序列化。毕竟,计算机无法直接理解人类的语言。
input_characters = sorted(list(input_characters)) # 这里排序是为了每一次
target_characters = sorted(list(target_characters)) # 构建的字典都一样
# 构建字符到数字的字典,每个字符对应一个数字
input_token_index = dict([(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict([(char, i) for i, char in enumerate(target_characters)])
input_token_index
{'一': 0,
'上': 1,
'不': 2,
'个': 3,
'为': 4,
'也': 5,
'事': 6,
'人': 7,
'以': 8,
'任': 9,
'何': 10,
'你': 11,
'信': 12,
'兴': 13,
'到': 14,
'发': 15,
'可': 16,
'后': 17,
'吗': 18,
'在': 19,
'好': 20,
'常': 21,
'很': 22,
'悔': 23,
'想': 24,
'感': 25,
'我': 26,
'手': 27,
'敢': 28,
'有': 29,
'机': 30,
'果': 31,
'样': 32,
'生': 33,
'的': 34,
'直': 35,
'相': 36,
'真': 37,
'知': 38,
'种': 39,
'简': 40,
'能': 41,
'苹': 42,
'要': 43,
'见': 44,
'觉': 45,
'身': 46,
'这': 47,
'道': 48,
'那': 49,
'非': 50,
'高': 51}
同样,实验需要定义一个将数值转化为字符的字典以备后用。
# 构建反向字典,每个数字对应一个字符
reverse_input_char_index = dict((i, char) for char, i in input_token_index.items())
reverse_target_char_index = dict((i, char) for char, i in target_token_index.items())
reverse_input_char_index
{0: '一',
1: '上',
2: '不',
3: '个',
4: '为',
5: '也',
6: '事',
7: '人',
8: '以',
9: '任',
10: '何',
11: '你',
12: '信',
13: '兴',
14: '到',
15: '发',
16: '可',
17: '后',
18: '吗',
19: '在',
20: '好',
21: '常',
22: '很',
23: '悔',
24: '想',
25: '感',
26: '我',
27: '手',
28: '敢',
29: '有',
30: '机',
31: '果',
32: '样',
33: '生',
34: '的',
35: '直',
36: '相',
37: '真',
38: '知',
39: '种',
40: '简',
41: '能',
42: '苹',
43: '要',
44: '见',
45: '觉',
46: '身',
47: '这',
48: '道',
49: '那',
50: '非',
51: '高'}
接下来,我们分别计算输入字符和输出单词的数量,以便后面对输入句子和输出句子进行独热编码。同时分别算出最长输入句子的长度和最长输出句子的长度。
num_encoder_tokens = len(input_characters) # 输入集不重复的字数
num_decoder_tokens = len(target_characters) # 输出集不重复的单词数
max_encoder_seq_length = max([len(txt) for txt in input_texts]) # 输入集最长句子的长度
max_decoder_seq_length = max([len(txt) for txt in target_texts]) # 输出集最长句子的长度
然后,需要将输入句子和输出句子都转化为向量的形式。这里需要注意的是,我们将输出句子转化为两份数据,一份为原始的输出句子序列,另一份为输出句子延后一个时刻的序列。两个序列分别作为解码器的输入和输出。
import numpy as np
# 创三个全为 0 的三维矩阵,第一维为样本数,第二维为句最大句子长度,第三维为每个字符的独热编码。
encoder_input_data = np.zeros(
(len(input_texts), max_encoder_seq_length, num_encoder_tokens), dtype="float32"
)
decoder_input_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens), dtype="float32"
)
decoder_target_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens), dtype="float32"
)
for i, (input_text, target_text) in enumerate(
zip(input_texts, target_texts)
): # 遍历输入集和输出集
for t, char in enumerate(input_text): # 遍历输入集每个句子
encoder_input_data[i, t, input_token_index[char]] = 1.0 # 字符对应的位置等于 1
for t, char in enumerate(target_text.split(" ")): # 遍历输出集的每个单词
# 解码器的输入序列
decoder_input_data[i, t, target_token_index[char]] = 1.0
if t > 0:
# 解码器的输出序列
decoder_target_data[i, t - 1, target_token_index[char]] = 1.0
在上面的代码中,decoder_input_data
表示解码器的输入序列,例如:【> I have a apple】。而
decoder_target_data
则表示解码器的输出序列,例如:【I have a apple <】。
查看一下独热编码的结果:
encoder_input_data[0]
array([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0.]], dtype=float32)
完成上面的数据预处理工作之后,现在来构建 seq2seq 模型。本次实验使用 TensorFlow Keras 来搭建模型。
训练 seq2seq 模型时,模型对输入的中文句子进行编码得到一个状态值,状态值也即保存了中文句子的信息。而在解码器网络中,将编码器得到的状态值作为解码器的初始状态值输入。
此外,语料数据是每一条中文句子对应一条英文句子。而中文句子作为编码器的输入,英文句子作为解码器的输出。但在解码器中,同样也需要输入,这里使用当前单词作为输入,选择下一个单词作为输出。如下图所示:

在上图中,解码器的
>
符号表示句子的开头,
<
符号表示句子的结尾。也即是说,对于数据集中的每个英文句子,都需要加上句子开头的标记符号
>
和结尾符号
<。训练时,我们的输入数据主要含有两份,分别是中文句子【我有一个苹果】,英文句子【>
I have a apple】,输出句子只有一份【I have a apple
<】。
按照上图所示的 seq2seq 模型,分别构建编码器模型和解码器模型。先来构建编码器模型:
import tensorflow as tf
latent_dim = 256 # 循环神经网络的神经单元数
# 编码器模型
encoder_inputs = tf.keras.Input(shape=(None, num_encoder_tokens)) # 编码器的输入
encoder = tf.keras.layers.LSTM(latent_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs) # 编码器的输出
encoder_states = [state_h, state_c] # 状态值
encoder_states
[<KerasTensor: shape=(None, 256) dtype=float32 (created by layer 'lstm')>,
<KerasTensor: shape=(None, 256) dtype=float32 (created by layer 'lstm')>]
这里我们使用 LSTM 来作为编码器和解码器,所以编码器的输出主要含有两个值,分别是 H 和 C 。现在使用这两个值作为解码器的初始状态值输入。
# 解码器模型
decoder_inputs = tf.keras.Input(shape=(None, num_decoder_tokens)) # 解码器输入
decoder_lstm = tf.keras.layers.LSTM(
latent_dim, return_sequences=True, return_state=True
)
# 初始化解码模型的状态值为 encoder_states
decoder_outputs, _, _ = decoder_lstm(decoder_inputs, initial_state=encoder_states)
# 连接一层全连接层,并使用 Softmax 求出每个时刻的输出
decoder_dense = tf.keras.layers.Dense(num_decoder_tokens, activation="softmax")
decoder_outputs = decoder_dense(decoder_outputs) # 解码器输出
decoder_outputs
<KerasTensor: shape=(None, None, 32) dtype=float32 (created by layer 'dense')>
构建好解码器之后,现在将编码器和解码器结合起来构成完整的 seq2seq 模型。
# 定义训练模型
model = tf.keras.Model([encoder_inputs, decoder_inputs], decoder_outputs)
model.summary()
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, None, 52)] 0 []
input_2 (InputLayer) [(None, None, 32)] 0 []
lstm (LSTM) [(None, 256), 316416 ['input_1[0][0]']
(None, 256),
(None, 256)]
lstm_1 (LSTM) [(None, None, 256), 295936 ['input_2[0][0]',
(None, 256), 'lstm[0][1]',
(None, 256)] 'lstm[0][2]']
dense (Dense) (None, None, 32) 8224 ['lstm_1[0][0]']
==================================================================================================
Total params: 620576 (2.37 MB)
Trainable params: 620576 (2.37 MB)
Non-trainable params: 0 (0.00 Byte)
__________________________________________________________________________________________________
接下来,选择损失函数和优化器,编译模型并完成训练。
# 定义优化算法和损失函数
model.compile(optimizer="adam", loss="categorical_crossentropy")
# 训练模型
model.fit(
[encoder_input_data, decoder_input_data],
decoder_target_data,
batch_size=10,
epochs=200,
)
Epoch 1/200
1/1 [==============================] - 1s 812ms/step - loss: 0.6418
Epoch 2/200
1/1 [==============================] - 0s 21ms/step - loss: 0.6394
Epoch 3/200
1/1 [==============================] - 0s 22ms/step - loss: 0.6370
Epoch 4/200
1/1 [==============================] - 0s 24ms/step - loss: 0.6345
Epoch 5/200
1/1 [==============================] - 0s 22ms/step - loss: 0.6320
Epoch 6/200
1/1 [==============================] - 0s 23ms/step - loss: 0.6293
Epoch 7/200
1/1 [==============================] - 0s 25ms/step - loss: 0.6265
Epoch 8/200
1/1 [==============================] - 0s 24ms/step - loss: 0.6236
Epoch 9/200
1/1 [==============================] - 0s 24ms/step - loss: 0.6202
Epoch 10/200
1/1 [==============================] - 0s 25ms/step - loss: 0.6157
Epoch 11/200
1/1 [==============================] - 0s 24ms/step - loss: 0.6090
Epoch 12/200
1/1 [==============================] - 0s 24ms/step - loss: 0.5997
Epoch 13/200
1/1 [==============================] - 0s 22ms/step - loss: 0.5908
Epoch 14/200
1/1 [==============================] - 0s 23ms/step - loss: 0.5896
Epoch 15/200
1/1 [==============================] - 0s 23ms/step - loss: 0.5937
Epoch 16/200
1/1 [==============================] - 0s 26ms/step - loss: 0.5934
Epoch 17/200
1/1 [==============================] - 0s 23ms/step - loss: 0.5878
Epoch 18/200
1/1 [==============================] - 0s 23ms/step - loss: 0.5832
Epoch 19/200
1/1 [==============================] - 0s 23ms/step - loss: 0.5827
Epoch 20/200
1/1 [==============================] - 0s 22ms/step - loss: 0.5810
Epoch 21/200
1/1 [==============================] - 0s 23ms/step - loss: 0.5729
Epoch 22/200
1/1 [==============================] - 0s 23ms/step - loss: 0.5602
Epoch 23/200
1/1 [==============================] - 0s 22ms/step - loss: 0.5480
Epoch 24/200
1/1 [==============================] - 0s 23ms/step - loss: 0.5394
Epoch 25/200
1/1 [==============================] - 0s 23ms/step - loss: 0.5340
Epoch 26/200
1/1 [==============================] - 0s 22ms/step - loss: 0.5307
Epoch 27/200
1/1 [==============================] - 0s 22ms/step - loss: 0.5283
Epoch 28/200
1/1 [==============================] - 0s 22ms/step - loss: 0.5263
Epoch 29/200
1/1 [==============================] - 0s 23ms/step - loss: 0.5239
Epoch 30/200
1/1 [==============================] - 0s 22ms/step - loss: 0.5211
Epoch 31/200
1/1 [==============================] - 0s 23ms/step - loss: 0.5185
Epoch 32/200
1/1 [==============================] - 0s 21ms/step - loss: 0.5167
Epoch 33/200
1/1 [==============================] - 0s 22ms/step - loss: 0.5153
Epoch 34/200
1/1 [==============================] - 0s 22ms/step - loss: 0.5140
Epoch 35/200
1/1 [==============================] - 0s 23ms/step - loss: 0.5126
Epoch 36/200
1/1 [==============================] - 0s 22ms/step - loss: 0.5113
Epoch 37/200
1/1 [==============================] - 0s 24ms/step - loss: 0.5102
Epoch 38/200
1/1 [==============================] - 0s 23ms/step - loss: 0.5090
Epoch 39/200
1/1 [==============================] - 0s 22ms/step - loss: 0.5077
Epoch 40/200
1/1 [==============================] - 0s 23ms/step - loss: 0.5064
Epoch 41/200
1/1 [==============================] - 0s 24ms/step - loss: 0.5051
Epoch 42/200
1/1 [==============================] - 0s 25ms/step - loss: 0.5038
Epoch 43/200
1/1 [==============================] - 0s 24ms/step - loss: 0.5025
Epoch 44/200
1/1 [==============================] - 0s 23ms/step - loss: 0.5013
Epoch 45/200
1/1 [==============================] - 0s 23ms/step - loss: 0.5003
Epoch 46/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4995
Epoch 47/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4987
Epoch 48/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4980
Epoch 49/200
1/1 [==============================] - 0s 24ms/step - loss: 0.4971
Epoch 50/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4958
Epoch 51/200
1/1 [==============================] - 0s 22ms/step - loss: 0.4943
Epoch 52/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4928
Epoch 53/200
1/1 [==============================] - 0s 22ms/step - loss: 0.4915
Epoch 54/200
1/1 [==============================] - 0s 22ms/step - loss: 0.4902
Epoch 55/200
1/1 [==============================] - 0s 24ms/step - loss: 0.4889
Epoch 56/200
1/1 [==============================] - 0s 24ms/step - loss: 0.4877
Epoch 57/200
1/1 [==============================] - 0s 28ms/step - loss: 0.4863
Epoch 58/200
1/1 [==============================] - 0s 24ms/step - loss: 0.4847
Epoch 59/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4828
Epoch 60/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4810
Epoch 61/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4795
Epoch 62/200
1/1 [==============================] - 0s 24ms/step - loss: 0.4781
Epoch 63/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4766
Epoch 64/200
1/1 [==============================] - 0s 20ms/step - loss: 0.4748
Epoch 65/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4726
Epoch 66/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4706
Epoch 67/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4689
Epoch 68/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4673
Epoch 69/200
1/1 [==============================] - 0s 24ms/step - loss: 0.4655
Epoch 70/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4634
Epoch 71/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4610
Epoch 72/200
1/1 [==============================] - 0s 22ms/step - loss: 0.4586
Epoch 73/200
1/1 [==============================] - 0s 24ms/step - loss: 0.4561
Epoch 74/200
1/1 [==============================] - 0s 22ms/step - loss: 0.4540
Epoch 75/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4520
Epoch 76/200
1/1 [==============================] - 0s 22ms/step - loss: 0.4498
Epoch 77/200
1/1 [==============================] - 0s 21ms/step - loss: 0.4474
Epoch 78/200
1/1 [==============================] - 0s 24ms/step - loss: 0.4450
Epoch 79/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4427
Epoch 80/200
1/1 [==============================] - 0s 22ms/step - loss: 0.4405
Epoch 81/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4384
Epoch 82/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4359
Epoch 83/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4334
Epoch 84/200
1/1 [==============================] - 0s 24ms/step - loss: 0.4308
Epoch 85/200
1/1 [==============================] - 0s 24ms/step - loss: 0.4284
Epoch 86/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4262
Epoch 87/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4240
Epoch 88/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4217
Epoch 89/200
1/1 [==============================] - 0s 22ms/step - loss: 0.4189
Epoch 90/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4158
Epoch 91/200
1/1 [==============================] - 0s 23ms/step - loss: 0.4126
Epoch 92/200
1/1 [==============================] - 0s 24ms/step - loss: 0.4101
Epoch 93/200
1/1 [==============================] - 0s 24ms/step - loss: 0.4069
Epoch 94/200
1/1 [==============================] - 0s 24ms/step - loss: 0.4064
Epoch 95/200
1/1 [==============================] - 0s 22ms/step - loss: 0.4014
Epoch 96/200
1/1 [==============================] - 0s 23ms/step - loss: 0.3980
Epoch 97/200
1/1 [==============================] - 0s 23ms/step - loss: 0.3968
Epoch 98/200
1/1 [==============================] - 0s 23ms/step - loss: 0.3911
Epoch 99/200
1/1 [==============================] - 0s 24ms/step - loss: 0.3878
Epoch 100/200
1/1 [==============================] - 0s 23ms/step - loss: 0.3878
Epoch 101/200
1/1 [==============================] - 0s 24ms/step - loss: 0.3815
Epoch 102/200
1/1 [==============================] - 0s 22ms/step - loss: 0.3781
Epoch 103/200
1/1 [==============================] - 0s 22ms/step - loss: 0.3764
Epoch 104/200
1/1 [==============================] - 0s 23ms/step - loss: 0.3726
Epoch 105/200
1/1 [==============================] - 0s 23ms/step - loss: 0.3682
Epoch 106/200
1/1 [==============================] - 0s 23ms/step - loss: 0.3650
Epoch 107/200
1/1 [==============================] - 0s 23ms/step - loss: 0.3633
Epoch 108/200
1/1 [==============================] - 0s 23ms/step - loss: 0.3579
Epoch 109/200
1/1 [==============================] - 0s 23ms/step - loss: 0.3545
Epoch 110/200
1/1 [==============================] - 0s 23ms/step - loss: 0.3532
Epoch 111/200
1/1 [==============================] - 0s 24ms/step - loss: 0.3490
Epoch 112/200
1/1 [==============================] - 0s 39ms/step - loss: 0.3451
Epoch 113/200
1/1 [==============================] - 0s 27ms/step - loss: 0.3429
Epoch 114/200
1/1 [==============================] - 0s 23ms/step - loss: 0.3403
Epoch 115/200
1/1 [==============================] - 0s 23ms/step - loss: 0.3357
Epoch 116/200
1/1 [==============================] - 0s 23ms/step - loss: 0.3329
Epoch 117/200
1/1 [==============================] - 0s 23ms/step - loss: 0.3307
Epoch 118/200
1/1 [==============================] - 0s 22ms/step - loss: 0.3261
Epoch 119/200
1/1 [==============================] - 0s 22ms/step - loss: 0.3219
Epoch 120/200
1/1 [==============================] - 0s 24ms/step - loss: 0.3192
Epoch 121/200
1/1 [==============================] - 0s 22ms/step - loss: 0.3147
Epoch 122/200
1/1 [==============================] - 0s 23ms/step - loss: 0.3104
Epoch 123/200
1/1 [==============================] - 0s 23ms/step - loss: 0.3066
Epoch 124/200
1/1 [==============================] - 0s 23ms/step - loss: 0.3043
Epoch 125/200
1/1 [==============================] - 0s 24ms/step - loss: 0.3002
Epoch 126/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2966
Epoch 127/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2930
Epoch 128/200
1/1 [==============================] - 0s 26ms/step - loss: 0.2905
Epoch 129/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2882
Epoch 130/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2853
Epoch 131/200
1/1 [==============================] - 0s 24ms/step - loss: 0.2823
Epoch 132/200
1/1 [==============================] - 0s 24ms/step - loss: 0.2789
Epoch 133/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2757
Epoch 134/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2731
Epoch 135/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2698
Epoch 136/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2663
Epoch 137/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2649
Epoch 138/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2613
Epoch 139/200
1/1 [==============================] - 0s 22ms/step - loss: 0.2583
Epoch 140/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2569
Epoch 141/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2537
Epoch 142/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2513
Epoch 143/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2496
Epoch 144/200
1/1 [==============================] - 0s 24ms/step - loss: 0.2467
Epoch 145/200
1/1 [==============================] - 0s 24ms/step - loss: 0.2448
Epoch 146/200
1/1 [==============================] - 0s 24ms/step - loss: 0.2432
Epoch 147/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2407
Epoch 148/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2392
Epoch 149/200
1/1 [==============================] - 0s 24ms/step - loss: 0.2375
Epoch 150/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2350
Epoch 151/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2330
Epoch 152/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2316
Epoch 153/200
1/1 [==============================] - 0s 25ms/step - loss: 0.2301
Epoch 154/200
1/1 [==============================] - 0s 24ms/step - loss: 0.2288
Epoch 155/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2272
Epoch 156/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2254
Epoch 157/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2238
Epoch 158/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2222
Epoch 159/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2202
Epoch 160/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2188
Epoch 161/200
1/1 [==============================] - 0s 24ms/step - loss: 0.2177
Epoch 162/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2163
Epoch 163/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2150
Epoch 164/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2140
Epoch 165/200
1/1 [==============================] - 0s 24ms/step - loss: 0.2130
Epoch 166/200
1/1 [==============================] - 0s 22ms/step - loss: 0.2123
Epoch 167/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2113
Epoch 168/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2100
Epoch 169/200
1/1 [==============================] - 0s 22ms/step - loss: 0.2089
Epoch 170/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2075
Epoch 171/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2065
Epoch 172/200
1/1 [==============================] - 0s 24ms/step - loss: 0.2052
Epoch 173/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2044
Epoch 174/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2032
Epoch 175/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2023
Epoch 176/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2012
Epoch 177/200
1/1 [==============================] - 0s 23ms/step - loss: 0.2005
Epoch 178/200
1/1 [==============================] - 0s 22ms/step - loss: 0.1994
Epoch 179/200
1/1 [==============================] - 0s 23ms/step - loss: 0.1986
Epoch 180/200
1/1 [==============================] - 0s 23ms/step - loss: 0.1975
Epoch 181/200
1/1 [==============================] - 0s 23ms/step - loss: 0.1967
Epoch 182/200
1/1 [==============================] - 0s 23ms/step - loss: 0.1957
Epoch 183/200
1/1 [==============================] - 0s 23ms/step - loss: 0.1949
Epoch 184/200
1/1 [==============================] - 0s 22ms/step - loss: 0.1939
Epoch 185/200
1/1 [==============================] - 0s 24ms/step - loss: 0.1932
Epoch 186/200
1/1 [==============================] - 0s 23ms/step - loss: 0.1920
Epoch 187/200
1/1 [==============================] - 0s 23ms/step - loss: 0.1913
Epoch 188/200
1/1 [==============================] - 0s 22ms/step - loss: 0.1900
Epoch 189/200
1/1 [==============================] - 0s 24ms/step - loss: 0.1897
Epoch 190/200
1/1 [==============================] - 0s 22ms/step - loss: 0.1881
Epoch 191/200
1/1 [==============================] - 0s 24ms/step - loss: 0.1882
Epoch 192/200
1/1 [==============================] - 0s 34ms/step - loss: 0.1860
Epoch 193/200
1/1 [==============================] - 0s 26ms/step - loss: 0.1868
Epoch 194/200
1/1 [==============================] - 0s 24ms/step - loss: 0.1843
Epoch 195/200
1/1 [==============================] - 0s 25ms/step - loss: 0.1846
Epoch 196/200
1/1 [==============================] - 0s 24ms/step - loss: 0.1832
Epoch 197/200
1/1 [==============================] - 0s 24ms/step - loss: 0.1823
Epoch 198/200
1/1 [==============================] - 0s 36ms/step - loss: 0.1823
Epoch 199/200
1/1 [==============================] - 0s 24ms/step - loss: 0.1804
Epoch 200/200
1/1 [==============================] - 0s 23ms/step - loss: 0.1808
<keras.src.callbacks.History at 0x28b5d2c20>
对于翻译任务,我们的目的是在编码器端输出一个中文句子,然后在解码器端得到一个输出的英文句子。而上面完成了模型的构建和训练。在模型的测试或者推理中,由于不知道输出序列的长度,所以要将编码器和解码器分开。
当模型训练完成之后,得到的是一个编码器和一个解码器。而在测试时,先将要翻译的中文句子输入编码器中,经过编码器得到一个状态向量 C 。
在训练时,我们将解码器的的第一个时刻的输入都设置为句子开头符号
>
。最后一个时刻的输出为句子结尾符号
<
。因此,在测试时,将句子开头符号
>
作为解码器第一个时刻的输入,预测出来的对应英文单词则作为下一个时刻的输入,依次循环。当输出为句子结尾符号
<
时,停止循环,将解码器所有的输出连起来得到一个翻译句子。整个过程如下图所示:

先来定义编码器模型,和前面构建模型时一样。这里需要注意的是
encoder_inputs
和
encoder_states
都是我们前面定义的变量。
# 重新定义编码器模型
encoder_model = tf.keras.Model(encoder_inputs, encoder_states)
encoder_model.summary()
Model: "model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, None, 52)] 0
lstm (LSTM) [(None, 256), 316416
(None, 256),
(None, 256)]
=================================================================
Total params: 316416 (1.21 MB)
Trainable params: 316416 (1.21 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
解码器模型的定义也类似。同样
decoder_lstm
和
decoder_dense
也是我们前面所定义的变量或函数。
""" 重新定义解码器模型 """
decoder_state_input_h = tf.keras.Input(shape=(latent_dim,)) # 解码器状态 H 输入
decoder_state_input_c = tf.keras.Input(shape=(latent_dim,)) # 解码器状态 C 输入
decoder_states_inputs = [decoder_state_input_h, decoder_state_input_c]
decoder_outputs, state_h, state_c = decoder_lstm(
decoder_inputs, initial_state=decoder_states_inputs
) # LSTM 模型输出
decoder_states = [state_h, state_c]
decoder_outputs = decoder_dense(decoder_outputs) # 连接一层全连接层
# 定义解码器模型
decoder_model = tf.keras.Model(
[decoder_inputs] + decoder_states_inputs, [decoder_outputs] + decoder_states
)
decoder_model.summary()
Model: "model_2"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_2 (InputLayer) [(None, None, 32)] 0 []
input_3 (InputLayer) [(None, 256)] 0 []
input_4 (InputLayer) [(None, 256)] 0 []
lstm_1 (LSTM) [(None, None, 256), 295936 ['input_2[0][0]',
(None, 256), 'input_3[0][0]',
(None, 256)] 'input_4[0][0]']
dense (Dense) (None, None, 32) 8224 ['lstm_1[1][0]']
==================================================================================================
Total params: 304160 (1.16 MB)
Trainable params: 304160 (1.16 MB)
Non-trainable params: 0 (0.00 Byte)
__________________________________________________________________________________________________
定义好上面的推理模型结构之后,现在就可以来对模型进行推理了,先来定义一个预测函数。
def decode_sequence(input_seq):
"""
decoder_dense:中文句子的向量形式。
"""
# 使用编码器预测出状态值
states_value = encoder_model.predict(input_seq)
# 构建解码器的第一个时刻的输入,即句子开头符号 >
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, target_token_index[">"]] = 1.0
stop_condition = False # 设置停止条件
decoded_sentence = [] # 存放结果
while not stop_condition:
# 预测出解码器的输出
output_tokens, h, c = decoder_model.predict([target_seq] + states_value)
# 求出对应的字符
sampled_token_index = np.argmax(output_tokens[0, -1, :])
sampled_char = reverse_target_char_index[sampled_token_index]
# 如果解码的输出为句子结尾符号 < ,则停止预测
if sampled_char == "<" or len(decoded_sentence) > max_decoder_seq_length:
stop_condition = True
if sampled_char != "<":
decoded_sentence.append(sampled_char)
target_seq = np.zeros((1, 1, num_decoder_tokens))
target_seq[0, 0, sampled_token_index] = 1.0
# 更新状态,用来继续送入下一个时刻
states_value = [h, c]
return decoded_sentence
基于 seq2seq 的机器翻译模型测试:
def answer(question):
# 将句子转化为一个数字矩阵
inseq = np.zeros((1, max_encoder_seq_length, num_encoder_tokens), dtype="float32")
for t, char in enumerate(question):
inseq[0, t, input_token_index[char]] = 1.0
# 输入模型得到输出结果
decoded_sentence = decode_sequence(inseq)
return decoded_sentence
test_sent = "我有一个苹果"
result = answer(test_sent)
print("中文句子:", test_sent)
print("翻译结果:", " ".join(result))
1/1 [==============================] - 0s 141ms/step
1/1 [==============================] - 0s 129ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 10ms/step
中文句子: 我有一个苹果
翻译结果: I have a apple
运行下面单元格代码输入你想要翻译的句子,例如【我很后悔】,【不敢相信能见到你】。需要注意的是,输入的字必须要在训练语料中出现过,否则会出现报错。
print("请输入中文句子,按回车键结束。")
test_sent = input()
result = answer(test_sent)
print("中文句子:", test_sent)
print("翻译结果:", " ".join(result))
请输入中文句子,按回车键结束。
我很后悔
1/1 [==============================] - 0s 15ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 8ms/step
1/1 [==============================] - 0s 9ms/step
1/1 [==============================] - 0s 9ms/step
中文句子: 我很后悔
翻译结果: I really regret
当你输入与训练语料不一样的句子时,模型不一定能准确翻译出来,这主要是由于这里只用了几个句子来训练模型,且所构建的模型十分简单。一般商用的神经机器翻译系统都是用 TB 级别的数据来训练的,而实验的重点是了解神经机器翻译系统的基本结构。
在前面实现的 seq2seq
中,是将编码的状态输出作为解码器的初始状态输入,且解码器的第一个时刻的输入为规定的句子开始符号
>。当然,这并不是 seq2seq
模型的固定形式。在其他学者的论文中,有的将编码器的最后一个状态的输出作为解码器第一个时刻的输入,如下图所示:

除此之外,还有学者编码器所编码得到的状态值 C 作为解码器所有时刻的输入,如下图所示:

上述这些都是 seq2seq 模型的变种结构。
76.5. 对话系统#
上面,我们主要讲解了 seq2seq 模型在神经机器翻译中的应用。接下来,实验将学习 seq2seq 的另一个重要的应用场景:对话系统。对话系统,往往也称之为聊天机器人。例如:淘宝客服、微软小冰、百度小度都属于聊天机器人的范畴。目前聊天机器人主要含有以下两种系统类型:检索式对话系统和生成式对话系统。
检索式对话系统就是通过对用户提问的问题进行解析,然后到数据库进行查找答案,再反馈给用户。例如,目前京东的机器人客服就属于这类系统。这类系统的特点是答案单一,但准确。适合做任务型的对话系统。
而生成式系统则是把用户的问题作为输入,系统根据具体问题,自动生成答案,然后反馈给用户。例如微软小冰就属于这类方法。这类系统的特点是答案不单一,且并不能保证答案一定正确。但这类系统回答生动有趣,所以非常适合用来做娱乐的聊天机器人。
检索式系统一般需要人工制定规则或识别出用户的问题意图,才能生成查询语句去数据库进行查询。而生成式系统则不需要这一过程。因此,我们现在就使用 seq2seq 模型来构建一个简易的对话系统。
使用 seq2seq 模型构建聊天机器人系统与构建机器翻译系统相似,所不同的是机器翻译系统的输出是另一种语言,而聊天机器人的输出是同一种语言。因此,使用 seq2seq 构建的聊天机器人也可以看做是同种语言之间的翻译。
模仿上面的翻译系统结构,这里使用状态值 C 作为解码器所有时刻的输入,具体如下图所示:

同时,输出答案的句子中不再需要开头标记符号
>,只需要句子结尾标记符号
<
即可。
同样,我们使用几组简单的语料数据:
input_texts = [
"今天天气怎么样",
"心情不好夸我几句",
"你是",
"月亮有多远",
"嗨",
"最近如何",
"你好吗",
"谁发明了电灯泡",
"你生气吗",
]
output = [
"貌似还不错哦",
"你唉算了吧",
"就不和你说",
"月亮从地球上平均约25英里",
"您好",
"挺好",
"很好,谢谢",
"托马斯·爱迪生",
"生气浪费电",
]
先给输出的句子添加结尾符号
<。
output_texts = []
for target_text in output: # 遍历每个句子
target_text = target_text + "<" # 每个句子都加上结尾符号
output_texts.append(target_text)
output_texts[0]
'貌似还不错哦<'
分别统计输入句子和输出句子出现的字符数,这里直接使用前面所定义的
count_char
函数来进行统计。
input_characters = count_char(input_texts)
target_characters = count_char(output_texts)
input_characters
{'不',
'么',
'了',
'亮',
'今',
'何',
'你',
'几',
'发',
'句',
'吗',
'嗨',
'多',
'天',
'夸',
'好',
'如',
'心',
'怎',
'情',
'我',
'明',
'是',
'最',
'月',
'有',
'样',
'气',
'泡',
'灯',
'生',
'电',
'谁',
'近',
'远'}
与上文相似,需要建立字典将文本序列化。
input_characters = sorted(list(input_characters)) # 这里排序是为了每次构建的字典一致
target_characters = sorted(list(target_characters))
# 构建字符到数字的字典
input_token_index = dict([(char, i) for i, char in enumerate(input_characters)])
target_token_index = dict([(char, i) for i, char in enumerate(target_characters)])
# 构建数字到字符的字典
reverse_input_char_index = dict((i, char) for char, i in input_token_index.items())
reverse_target_char_index = dict((i, char) for char, i in target_token_index.items())
接下来,我们分别计算输入字符和输出单词的数量,以便后面对输入句子和输出句子进行独热编码。同时分别算出最长输入句子的长度和最长输出句子的长度。
num_encoder_tokens = len(input_characters) # 输入集不重复的字数
num_decoder_tokens = len(target_characters) # 输出集不重复的字数
max_encoder_seq_length = max([len(txt) for txt in input_texts]) # 输入集最长句子的长度
max_decoder_seq_length = max([len(txt) for txt in output_texts]) # 输出集最长句子的长度
对所有的输出句子进行对齐操作,如果一个句子的长度小于最大长度,则在该句子的后面加句子结尾符号
<。
target_texts = []
for sent in output_texts: # 遍历每个句子
for i in range(len(sent), max_decoder_seq_length):
sent += "<" # 在每个长度小于最大长度的句子添加结尾符号
target_texts.append(sent)
target_texts
['貌似还不错哦<<<<<<<<',
'你唉算了吧<<<<<<<<<',
'就不和你说<<<<<<<<<',
'月亮从地球上平均约25英里<',
'您好<<<<<<<<<<<<',
'挺好<<<<<<<<<<<<',
'很好,谢谢<<<<<<<<<',
'托马斯·爱迪生<<<<<<<',
'生气浪费电<<<<<<<<<']
分别对输入句子和输出句子进行独热编码。
# 创三个全为 0 的三维矩阵,第一维为样本数,第二维为句最大句子长度,第三维为每个字符的独热编码。
encoder_input_data = np.zeros(
(len(input_texts), max_encoder_seq_length, num_encoder_tokens), dtype="float32"
)
decoder_input_data = np.zeros(
(len(input_texts), max_decoder_seq_length, num_decoder_tokens), dtype="float32"
)
for i, (input_text, target_text) in enumerate(zip(input_texts, target_texts)):
for t, char in enumerate(input_text):
encoder_input_data[i, t, input_token_index[char]] = 1.0
for t, char in enumerate(target_text):
decoder_input_data[i, t, target_token_index[char]] = 1.0
然后,我们定义并训练模型。这里的模型和前面所定义的机器翻译模型类似,只不过这里需要将编码器的状态值输出进行变换,使其形状由None,
latent_dim
变为
None,
max_decoder_seq_length,
latent_dim。
latent_dim
表示编码器输出状态值的向量长度,max_decoder_seq_length
表示回答数据集中最大句子长度。也就是说要将状态值 C 复制
max_decoder_seq_length
份,以便输入到解码器中。
在对状态值进行变换的过程中,使用到了 Keras 的 Lambda 函数,你可以阅读 官方文档 学习该函数的用法。
# 定义编码器模型
encoder_inputs = tf.keras.Input(shape=(None, num_encoder_tokens)) # 编码器输入
encoder = tf.keras.layers.LSTM(latent_dim, return_state=True)
encoder_outputs, state_h, state_c = encoder(encoder_inputs) # 编码器输出
encoder_state = [state_h, state_c] # 状态值
encoder_state = tf.keras.layers.Lambda(lambda x: tf.keras.layers.add(x))( # 合并状态值 H 和 C
encoder_state
)
encoder_state = tf.keras.layers.Lambda( # 添加一个维度
lambda x: tf.keras.backend.expand_dims(x, axis=1)
)(encoder_state)
# 复制前面所添加的维度
encoder_state3 = tf.keras.layers.Lambda(
lambda x: tf.tile(x, multiples=[1, max_decoder_seq_length, 1])
)(encoder_state)
解码器的定义也与翻译模型类似,但这里的初始状态值不是编码器的输出状态向量 C ,而是而是随机的一个值。且解码器每个时刻的输入都变为状态值 C。
# 定义解码器模型
decoder_lstm = tf.keras.layers.LSTM(
latent_dim, return_sequences=True, return_state=True
)
# 编码器的状态值输出作为解码器的输入
decoder_outputs, _, _ = decoder_lstm(encoder_state3)
# 添加一层全连接层
decoder_dense = tf.keras.layers.Dense(num_decoder_tokens, activation="softmax")
decoder_outputs = decoder_dense(decoder_outputs)
最后,结合编码器和解码器并构建出模型。
# 定义模型
model = tf.keras.Model(encoder_inputs, decoder_outputs)
model.summary()
Model: "model_3"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_5 (InputLayer) [(None, None, 35)] 0 []
lstm_2 (LSTM) [(None, 256), 299008 ['input_5[0][0]']
(None, 256),
(None, 256)]
lambda (Lambda) (None, 256) 0 ['lstm_2[0][1]',
'lstm_2[0][2]']
lambda_1 (Lambda) (None, 1, 256) 0 ['lambda[0][0]']
lambda_2 (Lambda) (None, 14, 256) 0 ['lambda_1[0][0]']
lstm_3 (LSTM) [(None, 14, 256), 525312 ['lambda_2[0][0]']
(None, 256),
(None, 256)]
dense_1 (Dense) (None, 14, 45) 11565 ['lstm_3[0][0]']
==================================================================================================
Total params: 835885 (3.19 MB)
Trainable params: 835885 (3.19 MB)
Non-trainable params: 0 (0.00 Byte)
__________________________________________________________________________________________________
训练模型时,需要注意输入的数据只有提问集的句子
encoder_input_data,因为解码器不需要回答集作为输入。
# 定义优化算法和损失函数
model.compile(optimizer="adam", loss="categorical_crossentropy")
# 训练模型
model.fit(encoder_input_data, decoder_input_data, batch_size=10, epochs=200)
Epoch 1/200
1/1 [==============================] - 1s 1s/step - loss: 3.8073
Epoch 2/200
1/1 [==============================] - 0s 17ms/step - loss: 3.7328
Epoch 3/200
1/1 [==============================] - 0s 24ms/step - loss: 3.6281
Epoch 4/200
1/1 [==============================] - 0s 16ms/step - loss: 3.4423
Epoch 5/200
1/1 [==============================] - 0s 16ms/step - loss: 3.0984
Epoch 6/200
1/1 [==============================] - 0s 16ms/step - loss: 2.5223
Epoch 7/200
1/1 [==============================] - 0s 18ms/step - loss: 1.9456
Epoch 8/200
1/1 [==============================] - 0s 24ms/step - loss: 1.8827
Epoch 9/200
1/1 [==============================] - 0s 19ms/step - loss: 2.0879
Epoch 10/200
1/1 [==============================] - 0s 19ms/step - loss: 2.1131
Epoch 11/200
1/1 [==============================] - 0s 20ms/step - loss: 1.9741
Epoch 12/200
1/1 [==============================] - 0s 22ms/step - loss: 1.8720
Epoch 13/200
1/1 [==============================] - 0s 19ms/step - loss: 1.7990
Epoch 14/200
1/1 [==============================] - 0s 19ms/step - loss: 1.7430
Epoch 15/200
1/1 [==============================] - 0s 20ms/step - loss: 1.7231
Epoch 16/200
1/1 [==============================] - 0s 19ms/step - loss: 1.7349
Epoch 17/200
1/1 [==============================] - 0s 19ms/step - loss: 1.7556
Epoch 18/200
1/1 [==============================] - 0s 20ms/step - loss: 1.7612
Epoch 19/200
1/1 [==============================] - 0s 20ms/step - loss: 1.7415
Epoch 20/200
1/1 [==============================] - 0s 20ms/step - loss: 1.7018
Epoch 21/200
1/1 [==============================] - 0s 21ms/step - loss: 1.6559
Epoch 22/200
1/1 [==============================] - 0s 20ms/step - loss: 1.6160
Epoch 23/200
1/1 [==============================] - 0s 18ms/step - loss: 1.5880
Epoch 24/200
1/1 [==============================] - 0s 20ms/step - loss: 1.5707
Epoch 25/200
1/1 [==============================] - 0s 20ms/step - loss: 1.5592
Epoch 26/200
1/1 [==============================] - 0s 21ms/step - loss: 1.5476
Epoch 27/200
1/1 [==============================] - 0s 20ms/step - loss: 1.5313
Epoch 28/200
1/1 [==============================] - 0s 20ms/step - loss: 1.5091
Epoch 29/200
1/1 [==============================] - 0s 19ms/step - loss: 1.4840
Epoch 30/200
1/1 [==============================] - 0s 26ms/step - loss: 1.4648
Epoch 31/200
1/1 [==============================] - 0s 20ms/step - loss: 1.4555
Epoch 32/200
1/1 [==============================] - 0s 20ms/step - loss: 1.4381
Epoch 33/200
1/1 [==============================] - 0s 23ms/step - loss: 1.4171
Epoch 34/200
1/1 [==============================] - 0s 26ms/step - loss: 1.4022
Epoch 35/200
1/1 [==============================] - 0s 20ms/step - loss: 1.3925
Epoch 36/200
1/1 [==============================] - 0s 20ms/step - loss: 1.3838
Epoch 37/200
1/1 [==============================] - 0s 20ms/step - loss: 1.3730
Epoch 38/200
1/1 [==============================] - 0s 22ms/step - loss: 1.3587
Epoch 39/200
1/1 [==============================] - 0s 20ms/step - loss: 1.3412
Epoch 40/200
1/1 [==============================] - 0s 20ms/step - loss: 1.3235
Epoch 41/200
1/1 [==============================] - 0s 20ms/step - loss: 1.3091
Epoch 42/200
1/1 [==============================] - 0s 22ms/step - loss: 1.2950
Epoch 43/200
1/1 [==============================] - 0s 21ms/step - loss: 1.2754
Epoch 44/200
1/1 [==============================] - 0s 21ms/step - loss: 1.2580
Epoch 45/200
1/1 [==============================] - 0s 21ms/step - loss: 1.2452
Epoch 46/200
1/1 [==============================] - 0s 21ms/step - loss: 1.2312
Epoch 47/200
1/1 [==============================] - 0s 20ms/step - loss: 1.2126
Epoch 48/200
1/1 [==============================] - 0s 21ms/step - loss: 1.1920
Epoch 49/200
1/1 [==============================] - 0s 20ms/step - loss: 1.1742
Epoch 50/200
1/1 [==============================] - 0s 22ms/step - loss: 1.1588
Epoch 51/200
1/1 [==============================] - 0s 21ms/step - loss: 1.1426
Epoch 52/200
1/1 [==============================] - 0s 20ms/step - loss: 1.1249
Epoch 53/200
1/1 [==============================] - 0s 21ms/step - loss: 1.1060
Epoch 54/200
1/1 [==============================] - 0s 21ms/step - loss: 1.0867
Epoch 55/200
1/1 [==============================] - 0s 20ms/step - loss: 1.0687
Epoch 56/200
1/1 [==============================] - 0s 26ms/step - loss: 1.0514
Epoch 57/200
1/1 [==============================] - 0s 23ms/step - loss: 1.0325
Epoch 58/200
1/1 [==============================] - 0s 22ms/step - loss: 1.0128
Epoch 59/200
1/1 [==============================] - 0s 20ms/step - loss: 0.9936
Epoch 60/200
1/1 [==============================] - 0s 20ms/step - loss: 0.9752
Epoch 61/200
1/1 [==============================] - 0s 27ms/step - loss: 0.9575
Epoch 62/200
1/1 [==============================] - 0s 23ms/step - loss: 0.9387
Epoch 63/200
1/1 [==============================] - 0s 25ms/step - loss: 0.9191
Epoch 64/200
1/1 [==============================] - 0s 21ms/step - loss: 0.9003
Epoch 65/200
1/1 [==============================] - 0s 21ms/step - loss: 0.8820
Epoch 66/200
1/1 [==============================] - 0s 21ms/step - loss: 0.8635
Epoch 67/200
1/1 [==============================] - 0s 21ms/step - loss: 0.8452
Epoch 68/200
1/1 [==============================] - 0s 21ms/step - loss: 0.8280
Epoch 69/200
1/1 [==============================] - 0s 21ms/step - loss: 0.8110
Epoch 70/200
1/1 [==============================] - 0s 21ms/step - loss: 0.7928
Epoch 71/200
1/1 [==============================] - 0s 22ms/step - loss: 0.7753
Epoch 72/200
1/1 [==============================] - 0s 21ms/step - loss: 0.7574
Epoch 73/200
1/1 [==============================] - 0s 22ms/step - loss: 0.7387
Epoch 74/200
1/1 [==============================] - 0s 21ms/step - loss: 0.7208
Epoch 75/200
1/1 [==============================] - 0s 26ms/step - loss: 0.7032
Epoch 76/200
1/1 [==============================] - 0s 21ms/step - loss: 0.6849
Epoch 77/200
1/1 [==============================] - 0s 20ms/step - loss: 0.6680
Epoch 78/200
1/1 [==============================] - 0s 21ms/step - loss: 0.6505
Epoch 79/200
1/1 [==============================] - 0s 21ms/step - loss: 0.6336
Epoch 80/200
1/1 [==============================] - 0s 21ms/step - loss: 0.6166
Epoch 81/200
1/1 [==============================] - 0s 19ms/step - loss: 0.5993
Epoch 82/200
1/1 [==============================] - 0s 22ms/step - loss: 0.5825
Epoch 83/200
1/1 [==============================] - 0s 32ms/step - loss: 0.5654
Epoch 84/200
1/1 [==============================] - 0s 23ms/step - loss: 0.5487
Epoch 85/200
1/1 [==============================] - 0s 24ms/step - loss: 0.5334
Epoch 86/200
1/1 [==============================] - 0s 22ms/step - loss: 0.5177
Epoch 87/200
1/1 [==============================] - 0s 20ms/step - loss: 0.5064
Epoch 88/200
1/1 [==============================] - 0s 20ms/step - loss: 0.4945
Epoch 89/200
1/1 [==============================] - 0s 21ms/step - loss: 0.4879
Epoch 90/200
1/1 [==============================] - 0s 20ms/step - loss: 0.4610
Epoch 91/200
1/1 [==============================] - 0s 21ms/step - loss: 0.4532
Epoch 92/200
1/1 [==============================] - 0s 22ms/step - loss: 0.4486
Epoch 93/200
1/1 [==============================] - 0s 20ms/step - loss: 0.4294
Epoch 94/200
1/1 [==============================] - 0s 20ms/step - loss: 0.4325
Epoch 95/200
1/1 [==============================] - 0s 21ms/step - loss: 0.4153
Epoch 96/200
1/1 [==============================] - 0s 21ms/step - loss: 0.4039
Epoch 97/200
1/1 [==============================] - 0s 21ms/step - loss: 0.3835
Epoch 98/200
1/1 [==============================] - 0s 20ms/step - loss: 0.3806
Epoch 99/200
1/1 [==============================] - 0s 21ms/step - loss: 0.3585
Epoch 100/200
1/1 [==============================] - 0s 20ms/step - loss: 0.3617
Epoch 101/200
1/1 [==============================] - 0s 21ms/step - loss: 0.3505
Epoch 102/200
1/1 [==============================] - 0s 21ms/step - loss: 0.3468
Epoch 103/200
1/1 [==============================] - 0s 20ms/step - loss: 0.3330
Epoch 104/200
1/1 [==============================] - 0s 21ms/step - loss: 0.3320
Epoch 105/200
1/1 [==============================] - 0s 20ms/step - loss: 0.3091
Epoch 106/200
1/1 [==============================] - 0s 21ms/step - loss: 0.3153
Epoch 107/200
1/1 [==============================] - 0s 20ms/step - loss: 0.3073
Epoch 108/200
1/1 [==============================] - 0s 21ms/step - loss: 0.2944
Epoch 109/200
1/1 [==============================] - 0s 24ms/step - loss: 0.3032
Epoch 110/200
1/1 [==============================] - 0s 21ms/step - loss: 0.2891
Epoch 111/200
1/1 [==============================] - 0s 21ms/step - loss: 0.2723
Epoch 112/200
1/1 [==============================] - 0s 21ms/step - loss: 0.2766
Epoch 113/200
1/1 [==============================] - 0s 19ms/step - loss: 0.2665
Epoch 114/200
1/1 [==============================] - 0s 22ms/step - loss: 0.2564
Epoch 115/200
1/1 [==============================] - 0s 21ms/step - loss: 0.2538
Epoch 116/200
1/1 [==============================] - 0s 22ms/step - loss: 0.2409
Epoch 117/200
1/1 [==============================] - 0s 21ms/step - loss: 0.2400
Epoch 118/200
1/1 [==============================] - 0s 22ms/step - loss: 0.2330
Epoch 119/200
1/1 [==============================] - 0s 21ms/step - loss: 0.2254
Epoch 120/200
1/1 [==============================] - 0s 21ms/step - loss: 0.2232
Epoch 121/200
1/1 [==============================] - 0s 22ms/step - loss: 0.2152
Epoch 122/200
1/1 [==============================] - 0s 21ms/step - loss: 0.2141
Epoch 123/200
1/1 [==============================] - 0s 22ms/step - loss: 0.2086
Epoch 124/200
1/1 [==============================] - 0s 22ms/step - loss: 0.2057
Epoch 125/200
1/1 [==============================] - 0s 21ms/step - loss: 0.2024
Epoch 126/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1967
Epoch 127/200
1/1 [==============================] - 0s 26ms/step - loss: 0.1936
Epoch 128/200
1/1 [==============================] - 0s 23ms/step - loss: 0.1876
Epoch 129/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1832
Epoch 130/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1797
Epoch 131/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1753
Epoch 132/200
1/1 [==============================] - 0s 22ms/step - loss: 0.1738
Epoch 133/200
1/1 [==============================] - 0s 20ms/step - loss: 0.1717
Epoch 134/200
1/1 [==============================] - 0s 22ms/step - loss: 0.1711
Epoch 135/200
1/1 [==============================] - 0s 20ms/step - loss: 0.1736
Epoch 136/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1666
Epoch 137/200
1/1 [==============================] - 0s 27ms/step - loss: 0.1596
Epoch 138/200
1/1 [==============================] - 0s 20ms/step - loss: 0.1545
Epoch 139/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1520
Epoch 140/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1521
Epoch 141/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1511
Epoch 142/200
1/1 [==============================] - 0s 23ms/step - loss: 0.1479
Epoch 143/200
1/1 [==============================] - 0s 19ms/step - loss: 0.1419
Epoch 144/200
1/1 [==============================] - 0s 23ms/step - loss: 0.1384
Epoch 145/200
1/1 [==============================] - 0s 23ms/step - loss: 0.1376
Epoch 146/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1364
Epoch 147/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1361
Epoch 148/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1320
Epoch 149/200
1/1 [==============================] - 0s 20ms/step - loss: 0.1277
Epoch 150/200
1/1 [==============================] - 0s 20ms/step - loss: 0.1247
Epoch 151/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1235
Epoch 152/200
1/1 [==============================] - 0s 20ms/step - loss: 0.1227
Epoch 153/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1214
Epoch 154/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1206
Epoch 155/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1180
Epoch 156/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1152
Epoch 157/200
1/1 [==============================] - 0s 20ms/step - loss: 0.1120
Epoch 158/200
1/1 [==============================] - 0s 20ms/step - loss: 0.1096
Epoch 159/200
1/1 [==============================] - 0s 20ms/step - loss: 0.1076
Epoch 160/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1058
Epoch 161/200
1/1 [==============================] - 0s 22ms/step - loss: 0.1046
Epoch 162/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1040
Epoch 163/200
1/1 [==============================] - 0s 22ms/step - loss: 0.1046
Epoch 164/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1063
Epoch 165/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1124
Epoch 166/200
1/1 [==============================] - 0s 23ms/step - loss: 0.1100
Epoch 167/200
1/1 [==============================] - 0s 21ms/step - loss: 0.1071
Epoch 168/200
1/1 [==============================] - 0s 21ms/step - loss: 0.0974
Epoch 169/200
1/1 [==============================] - 0s 21ms/step - loss: 0.0948
Epoch 170/200
1/1 [==============================] - 0s 23ms/step - loss: 0.0961
Epoch 171/200
1/1 [==============================] - 0s 22ms/step - loss: 0.0946
Epoch 172/200
1/1 [==============================] - 0s 21ms/step - loss: 0.0925
Epoch 173/200
1/1 [==============================] - 0s 20ms/step - loss: 0.0898
Epoch 174/200
1/1 [==============================] - 0s 21ms/step - loss: 0.0881
Epoch 175/200
1/1 [==============================] - 0s 21ms/step - loss: 0.0872
Epoch 176/200
1/1 [==============================] - 0s 20ms/step - loss: 0.0860
Epoch 177/200
1/1 [==============================] - 0s 21ms/step - loss: 0.0844
Epoch 178/200
1/1 [==============================] - 0s 20ms/step - loss: 0.0821
Epoch 179/200
1/1 [==============================] - 0s 21ms/step - loss: 0.0822
Epoch 180/200
1/1 [==============================] - 0s 20ms/step - loss: 0.0817
Epoch 181/200
1/1 [==============================] - 0s 21ms/step - loss: 0.0783
Epoch 182/200
1/1 [==============================] - 0s 21ms/step - loss: 0.0775
Epoch 183/200
1/1 [==============================] - 0s 21ms/step - loss: 0.0780
Epoch 184/200
1/1 [==============================] - 0s 22ms/step - loss: 0.0756
Epoch 185/200
1/1 [==============================] - 0s 20ms/step - loss: 0.0743
Epoch 186/200
1/1 [==============================] - 0s 21ms/step - loss: 0.0738
Epoch 187/200
1/1 [==============================] - 0s 21ms/step - loss: 0.0718
Epoch 188/200
1/1 [==============================] - 0s 20ms/step - loss: 0.0715
Epoch 189/200
1/1 [==============================] - 0s 20ms/step - loss: 0.0710
Epoch 190/200
1/1 [==============================] - 0s 20ms/step - loss: 0.0693
Epoch 191/200
1/1 [==============================] - 0s 20ms/step - loss: 0.0688
Epoch 192/200
1/1 [==============================] - 0s 20ms/step - loss: 0.0676
Epoch 193/200
1/1 [==============================] - 0s 20ms/step - loss: 0.0661
Epoch 194/200
1/1 [==============================] - 0s 21ms/step - loss: 0.0657
Epoch 195/200
1/1 [==============================] - 0s 21ms/step - loss: 0.0646
Epoch 196/200
1/1 [==============================] - 0s 31ms/step - loss: 0.0636
Epoch 197/200
1/1 [==============================] - 0s 22ms/step - loss: 0.0633
Epoch 198/200
1/1 [==============================] - 0s 19ms/step - loss: 0.0623
Epoch 199/200
1/1 [==============================] - 0s 20ms/step - loss: 0.0621
Epoch 200/200
1/1 [==============================] - 0s 20ms/step - loss: 0.0623
<keras.src.callbacks.History at 0x28c2c3c40>
同样,我们需要构建推理的编码器模型和解码器模型。推理模型与前面所训练的模型权值是共享的。
# 重新定义编码器模型
encoder_model = tf.keras.Model(encoder_inputs, encoder_state3)
encoder_model.summary()
Model: "model_4"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_5 (InputLayer) [(None, None, 35)] 0 []
lstm_2 (LSTM) [(None, 256), 299008 ['input_5[0][0]']
(None, 256),
(None, 256)]
lambda (Lambda) (None, 256) 0 ['lstm_2[0][1]',
'lstm_2[0][2]']
lambda_1 (Lambda) (None, 1, 256) 0 ['lambda[0][0]']
lambda_2 (Lambda) (None, 14, 256) 0 ['lambda_1[0][0]']
==================================================================================================
Total params: 299008 (1.14 MB)
Trainable params: 299008 (1.14 MB)
Non-trainable params: 0 (0.00 Byte)
__________________________________________________________________________________________________
# 重新定义解码器模型
decoder_inputs = tf.keras.Input(shape=(None, latent_dim))
outputs, _, _ = decoder_lstm(decoder_inputs)
outputs = decoder_dense(outputs) # 全连接层
decoder_model = tf.keras.Model(decoder_inputs, outputs)
decoder_model.summary()
Model: "model_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_6 (InputLayer) [(None, None, 256)] 0
lstm_3 (LSTM) multiple 525312
dense_1 (Dense) multiple 11565
=================================================================
Total params: 536877 (2.05 MB)
Trainable params: 536877 (2.05 MB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
然后定义用于输出预测序列的函数。
def decode_sequence(input_seq):
# 使用编码器预测出状态值
states_value = encoder_model.predict(input_seq)
# 使用解码器预测数结果
output_tokens = decoder_model.predict(states_value)
decoded_sentence = [] # 存放结果
# 遍历结果的所有时刻,求出每个时刻的输出对应的字符
for i in range(max_decoder_seq_length):
sampled_token_index = np.argmax(output_tokens[0, i, :])
sampled_char = reverse_target_char_index[sampled_token_index]
if sampled_char != "<":
decoded_sentence.append(sampled_char)
return decoded_sentence
一切就绪,现在就可以测试我们刚刚训练好的对话系统了。
def answer(question):
# 将输入的句子转化为对应的矩阵
inseq = np.zeros((1, max_encoder_seq_length, num_encoder_tokens), dtype="float32")
for t, char in enumerate(question):
inseq[0, t, input_token_index[char]] = 1.0
# 输入模型得到结果
decoded_sentence = decode_sequence(inseq)
return decoded_sentence
test_sent = "今天天气怎么样"
result = answer(test_sent)
print("提问:", test_sent)
print("回答:", "".join(result))
1/1 [==============================] - 0s 119ms/step
1/1 [==============================] - 0s 131ms/step
提问: 今天天气怎么样
回答: 貌似还不错哦
运行下面单元格代码输入你想要翻译的句子,例如【嗨】、【你夸我几句】、【月亮多远】。这里需要注意的是,输入的字必须要在训练语料中出现过,否则会报错。
print("请输入中文句子,按回车键结束。")
test_sent = input()
result = answer(test_sent)
print("中文句子:", test_sent)
print("翻译结果:", "".join(result))
请输入中文句子,按回车键结束。
月亮多远
1/1 [==============================] - 0s 17ms/step
1/1 [==============================] - 0s 13ms/step
中文句子: 月亮多远
翻译结果: 月亮从地球上平均25英里
由于 seq2seq 模型训练比较慢,所以这里同机器翻译一样,只使用几个句子进行训练,所以整体效果不佳。如果你有兴趣,可以在线下使用 Datasets for Training Chatbot System,ChatterBot Language Training Corpus,Douban Conversation Corpus 等数据集来训练模型。
Note
我们依据实验中代码,通过较大的语料数据训练了一个对话模型(自动对对联),大家可以 参考。
76.6. 总结#
本次实验主要讲解了 seq2seq 模型的原理,并介绍了其在神经机器翻译和对话系统中的应用。但受限于简单模型和语料数据,实验训练的效果并不理想。实际上,seq2seq 模型还可以做许多事情,例如:自动文本摘要,自动标题生成,成语接龙等。如果你有兴趣,可以自行了解学习。
相关链接
○ 欢迎分享本文链接到你的社交账号、博客、论坛等。更多的外链会增加搜索引擎对本站收录的权重,从而让更多人看到这些内容。