
42. 机器学习模型推理与部署#
42.1. 介绍#
机器学习工程会利用本地训练的模型进行推理,并在有必要的时候将其部署到云端。本次实验将学会如何对 scikit-learn 构建的模型进行保存,部署和推理。
42.2. 知识点#
模型保存
模型部署
模型推理
到目前为止,相信你已经对机器学习过程非常熟悉。一般情况下,我们会使用训练数据构建模型,然后再用验证数据或测试数据来评估模型。实际上,评估模型的过程在前面也称为预测和评价。
42.3. 模型推理#
实际上,用训练好的模型对新数据进行预测,在机器学习工程上有一个更专业的名词叫做「推理 Inference」。下图详细说明了神经网络模型训练和推理的过程。通过训练集构建的神经网络对新输入数据进行预测,就是推理。
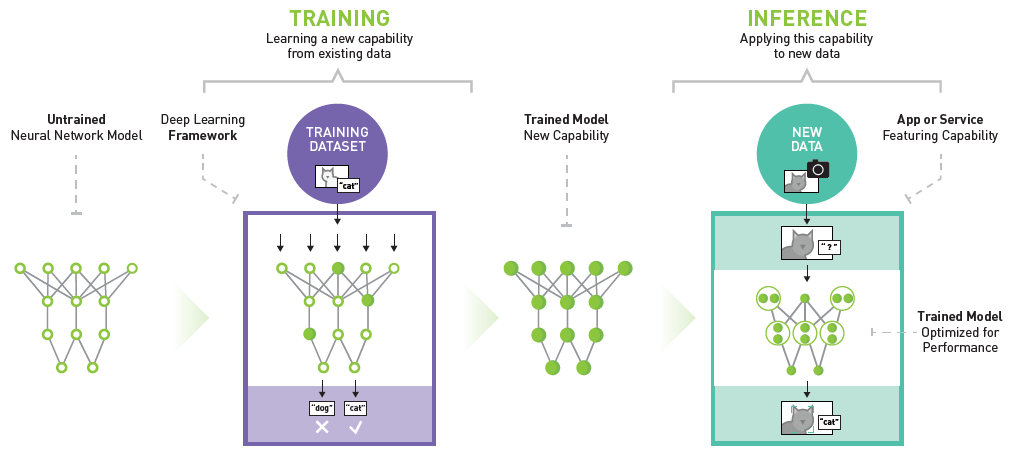
一般情况下,推理又分为:静态推理与动态推理。
静态推理很好理解,我们通过集中对批量数据进行推理,并将结果存放在数据表或数据库中。当有需要的时候,再直接通过查询来获得推理结果。
而动态推理一般表示我们将模型部署到服务器中。当有需要时,通过向服务器发送请求来获得模型返回的预测结果。与静态推理不同的是,动态推理的过程是实时计算的,而静态推理是提前批量处理好的。
当然,静态和动态推理各有优缺点。静态推理适合于对大批量数据进行处理,因为动态推理面对大数据量时非常耗时。但是静态推理无法实时更新,而动态推理的结果是即时计算结果。
静态推理相信大家都很熟悉了,因为前面的内容中,我们对新数据预测实际上就类似于静态推理的过程。你只需要使用
scikit-learn 提供的
predict
操作即可完成。接下来,我们重点讨论动态推理的过程,并教你使用
RESTful
API 的方式部署 scikit-learn 模型并完成动态推理。
42.4. 模型部署#
想要部署 scikit-learn 模型,当然需要先完成模型训练。
下面,我们训练一个泰坦尼克号生存推理模型。数据集通过 seaborn 进行加载,并完成预览。
from seaborn import load_dataset
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings("ignore") # 忽略模块变动警告
df = load_dataset("titanic") # 加载泰坦尼克数据集
df
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 886 | 0 | 2 | male | 27.0 | 0 | 0 | 13.0000 | S | Second | man | True | NaN | Southampton | no | True |
| 887 | 1 | 1 | female | 19.0 | 0 | 0 | 30.0000 | S | First | woman | False | B | Southampton | yes | True |
| 888 | 0 | 3 | female | NaN | 1 | 2 | 23.4500 | S | Third | woman | False | NaN | Southampton | no | False |
| 889 | 1 | 1 | male | 26.0 | 0 | 0 | 30.0000 | C | First | man | True | C | Cherbourg | yes | True |
| 890 | 0 | 3 | male | 32.0 | 0 | 0 | 7.7500 | Q | Third | man | True | NaN | Queenstown | no | True |
891 rows × 15 columns
可以看的,数据集一共包含 15 列共 891
个样本。我们选择乘客仓位
pclass,性别
sex,登船港口
embarked
等 3 个特征,并使用
alive
是否存活作为目标值。
X = df[["pclass", "sex", "embarked"]] # 特征
y = df["alive"] # 目标
训练之前,我们先对特征数据进行独热编码,独热编码的方法前面已经介绍过了。
X = pd.get_dummies(X) # 独热编码
X.head()
| pclass | sex_female | sex_male | embarked_C | embarked_Q | embarked_S | |
|---|---|---|---|---|---|---|
| 0 | 3 | False | True | False | False | True |
| 1 | 1 | True | False | True | False | False |
| 2 | 3 | True | False | False | False | True |
| 3 | 1 | True | False | False | False | True |
| 4 | 3 | False | True | False | False | True |
接下来,就可以开始训练了。这里使用随机森林方法建模,并使用交叉验证来查看模型的表现。
from sklearn.model_selection import cross_val_score
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier() # 随机森林
np.mean(cross_val_score(model, X, y, cv=5)) # 5 次交叉验证求平均
0.8114556525014125
交叉验证显示模型的分类准确度大约为 81%。
为了方便模型的部署,我们需要把训练好的模型存储下来。这里可以使用
scikit-learn 提供的
sklearn.externals.joblib,将模型存为
.pkl
二进制文件。保存模型的方法非常简单,直接阅读下面的代码。
import joblib
model.fit(X, y) # 训练模型
joblib.dump(model, "titanic.pkl") # 保存模型
['titanic.pkl']
现在,有了模型文件,那么就可以部署模型了。我们打算将模型部署到云端(本地测试),这里借助于 Flask 来实现。Flask 是 Python 著名的 Web 应用框架,可以用于构建一个 RESTful API。由于本课程未涉及 Flask 的内容,下面的代码大家需自行结合 官方文档 理解。
%writefile predict.py
from flask import Flask, request, jsonify
import joblib
import pandas as pd
app = Flask(__name__)
@app.route("/", methods=["POST"]) # 请求方法为 POST
def predict():
json_ = request.json # 解析请求数据
query_df = pd.DataFrame(json_) # 将 JSON 变为 DataFrame
columns_onehot = [
"pclass",
"sex_female",
"sex_male",
"embarked_C",
"embarked_Q",
"embarked_S",
] # 独热编码 DataFrame 列名
query = pd.get_dummies(query_df).reindex(
columns=columns_onehot, fill_value=0
) # 将请求数据 DataFrame 处理成独热编码样式
clf = joblib.load("titanic.pkl") # 加载模型
prediction = clf.predict(query) # 模型推理
return jsonify({"prediction": list(prediction)}) # 返回推理结果
Overwriting predict.py
首先在终端执行
predict.py
启动 Flask app。
$ python predict.py
* Serving Flask app "predict" (lazy loading)
* Environment: production
WARNING: Do not use the development server in a production environment.
Use a production WSGI server instead.
* Debug mode: off
* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
开启新终端向目的地址发送请求。
In [1]: import requests
In [2]: sample = [{"pclass": 1, "sex": "male", "embarked": "C"}, {"pclass": 2, "sex": "female", "embarked": "S"}]
In [3]: requests.post(url='http://127.0.0.1:5000', json=sample).content
Out[3]: b'{"prediction":["no","yes"]}\n'
这里,我们给出实验示例模型部署在云端的测试地址:https://titanic-demo.onrender.com,你可以直接获得测试结果:
import requests
# 向服务器发送请求获得预测结果
sample = [
{"pclass": 1, "sex": "male", "embarked": "C"},
{"pclass": 2, "sex": "female", "embarked": "S"},
{"pclass": 3, "sex": "male", "embarked": "Q"},
{"pclass": 3, "sex": "female", "embarked": "S"},
]
# 稍等片刻,Render 线上服务存在冷却启动时间
requests.post(url="https://titanic-demo.onrender.com", json=sample).content
b'{"predict":["no","yes","no","no"]}\n'
你可以阅读并参考该项目的 源代码。
42.5. 总结#
本次课程学习了 scikit-learn 模型的保存,部署与动态推理。由于涉及到 Flask 的使用,部分知识需要学员额外自行补充学习。不过,相信你从实验的内容中已经能够体会完整的过程。实际上,随着云技术的发展,线上部署模型变得更加方便,类似于 Google Cloud 推出的云端函数或者 AWS Lambda 功能,都能够在无服务器情况下实现机器学习模型快速部署,有兴趣可以自行搜索学习。
○ 欢迎分享本文链接到你的社交账号、博客、论坛等。更多的外链会增加搜索引擎对本站收录的权重,从而让更多人看到这些内容。