
5. 比特币价格预测及绘图#
5.1. 介绍#
比特币(英语:Bitcoin,缩写:BTC)被部分观点认为是一种去中心化,非普遍全球可支付的电子加密货币,而多数国家则认为比特币属于虚拟商品,并非货币。比特币由中本聪(化名)于 2009 年 1 月 3 日,基于无国界的对等网络,用共识主动性开源软件发明创立。
5.2. 知识点#
数据准备
3 次多项式回归预测挑战
N 次多项式回归预测绘图
自比特币出现至今为止,其一直是目前法币市场总值最高的数字货币。一段时间以来,比特币的价值饱受质疑。有人认为是严重的「泡沫」,也有人认为是物有所值。但无论哪一种观点,我们都见证了比特币暴涨暴跌。本次挑战收集到了 2010-2018 年比特币历史数据。其中包含交易价格、区块数量、交易费率等信息。我们将尝试使用多项式回归和岭回归方法来预测比特币价格变化趋势。
5.3. 数据准备#
首先,需要导入比特币历史数据集,并预览数据集前 5
行。数据集名称为
challenge-2-bitcoin.csv。
# 数据集链接
https://cdn.aibydoing.com/aibydoing/files/challenge-2-bitcoin.csv
Exercise 5.1
挑战:使用 Pandas 加载数据集 CSV 文件,并预览前 5 行数据。
import pandas as pd
## 代码开始 ### (≈ 2 行代码)
df = None
## 代码结束 ###
参考答案 Exercise 5.1
# 下载数据集
wget -nc https://cdn.aibydoing.com/aibydoing/files/challenge-2-bitcoin.csv
import pandas as pd
### 代码开始 ### (≈ 2 行代码)
df = pd.read_csv('challenge-2-bitcoin.csv', header=0)
df.head()
### 代码结束 ###
期望输出
| Date | btc_market_price | btc_total_bitcoins | btc_market_cap | btc_trade_volume | btc_blocks_size | btc_avg_block_size | btc_n_orphaned_blocks | btc_n_transactions_per_block | btc_median_confirmation_time | ... | btc_cost_per_transaction_percent | btc_cost_per_transaction | btc_n_unique_addresses | btc_n_transactions | btc_n_transactions_total | btc_n_transactions_excluding_popular | btc_n_transactions_excluding_chains_longer_than_100 | btc_output_volume | btc_estimated_transaction_volume | btc_estimated_transaction_volume_usd | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2010-02-23 00:00:00 | 0.0 | 2110700.0 | 0.0 | 0.0 | 0.0 | 0.000216 | 0.0 | 1.0 | 0.0 | ... | 25100.000000 | 0.0 | 252.0 | 252.0 | 42613.0 | 252.0 | 252.0 | 12600.0 | 50.0 | 0.0 |
| 1 | 2010-02-24 00:00:00 | 0.0 | 2120200.0 | 0.0 | 0.0 | 0.0 | 0.000282 | 0.0 | 1.0 | 0.0 | ... | 179.245283 | 0.0 | 195.0 | 196.0 | 42809.0 | 196.0 | 196.0 | 14800.0 | 5300.0 | 0.0 |
| 2 | 2010-02-25 00:00:00 | 0.0 | 2127600.0 | 0.0 | 0.0 | 0.0 | 0.000227 | 0.0 | 1.0 | 0.0 | ... | 1057.142857 | 0.0 | 150.0 | 150.0 | 42959.0 | 150.0 | 150.0 | 8100.0 | 700.0 | 0.0 |
| 3 | 2010-02-26 00:00:00 | 0.0 | 2136100.0 | 0.0 | 0.0 | 0.0 | 0.000319 | 0.0 | 1.0 | 0.0 | ... | 64.582059 | 0.0 | 176.0 | 176.0 | 43135.0 | 176.0 | 176.0 | 29349.0 | 13162.0 | 0.0 |
| 4 | 2010-02-27 00:00:00 | 0.0 | 2144750.0 | 0.0 | 0.0 | 0.0 | 0.000223 | 0.0 | 1.0 | 0.0 | ... | 1922.222222 | 0.0 | 176.0 | 176.0 | 43311.0 | 176.0 | 176.0 | 9101.0 | 450.0 | 0.0 |
可以看到,原数据集中包含的数据较多,本次挑战中只使用其中的 3 列,分布是:比特币市场价格、比特币总量、比特币交易费用。它们对应的列名依次为:btc_market_price,btc_total_bitcoins,btc_transaction_fees。
Exercise 5.2
挑战:分离出仅包含
btc_market_price,btc_total_bitcoins,btc_transaction_fees
列的 DataFrame,并定义为变量
data。
## 代码开始 ### (≈ 1 行代码)
data = None
## 代码结束 ###
参考答案 Exercise 5.2
### 代码开始 ### (≈ 1 行代码)
data = df[['btc_market_price','btc_total_bitcoins', 'btc_transaction_fees']]
### 代码结束 ###
运行测试
data.head()
期望输出
| btc_market_price | btc_total_bitcoins | btc_transaction_fees | |
|---|---|---|---|
| 0 | 0.0 | 2110700.0 | 0.0 |
| 1 | 0.0 | 2120200.0 | 0.0 |
| 2 | 0.0 | 2127600.0 | 0.0 |
| 3 | 0.0 | 2136100.0 | 0.0 |
| 4 | 0.0 | 2144750.0 | 0.0 |
下面,我们将 3 列数据,分别绘制在横向排列的 3 张子图中。
Exercise 5.3
挑战:分别绘制
data
数据集 3 列数据的线形图,并以横向子图排列。
规定:需设置各图横纵轴名称,横轴统一为
time,纵轴为各自列名称。
提示:使用
set_xlabel()
设置横轴名称。
from matplotlib import pyplot as plt
%matplotlib inline
fig, axes = plt.subplots(1, 3, figsize=(16, 5))
## 代码开始 ### (≈ 9 行代码)
## 代码结束 ###
参考答案 Exercise 5.3
from matplotlib import pyplot as plt
%matplotlib inline
fig, axes = plt.subplots(1, 3, figsize=(16, 5))
### 代码开始 ### (≈ 9 行代码)
axes[0].plot(data['btc_market_price'], 'green')
axes[0].set_xlabel('time')
axes[0].set_ylabel('btc_market_price')
axes[1].plot(data['btc_total_bitcoins'], 'blue')
axes[1].set_xlabel('time')
axes[1].set_ylabel('btc_total_bitcoins')
axes[2].plot(data['btc_transaction_fees'], 'brown')
axes[2].set_xlabel('time')
axes[2].set_ylabel('btc_transaction_fees')
### 代码结束 ###
期望输出(可忽略颜色)
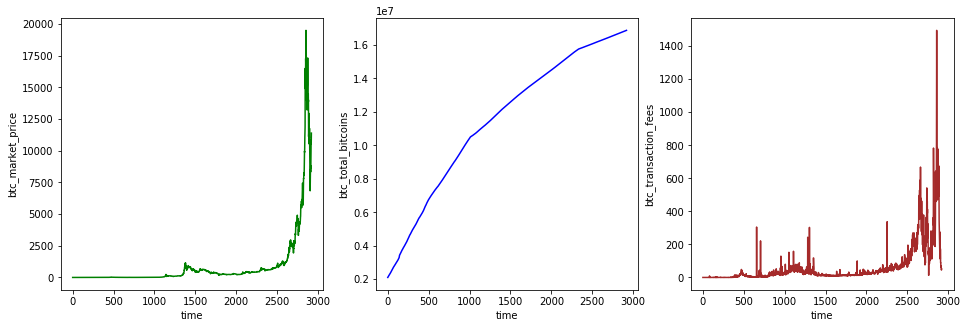
本次挑战中,数据集的特征(Features)是「比特币总量」和「比特币交易费用」,而目标值为「比特币市场价格」。所以,下面将数据集拆分为训练集和测试集。其中,训练集占 70%,而测试集占 30%。
Exercise 5.4
挑战:划分
data
数据集,使得训练集占 70%,而测试集占 30%。
规定:训练集特征、训练集目标、测试集特征、测试集目标分别定义为
X_train,
y_train,
X_test,
y_test,并作为
split_dataset()
函数返回值。
def split_dataset():
"""
参数:
无
返回:
X_train, y_train, X_test, y_test -- 训练集特征、训练集目标、测试集特征、测试集目标
"""
### 代码开始 ### (≈ 6 行代码)
### 代码结束 ###
return X_train, y_train, X_test, y_test
参考答案 Exercise 5.4
def split_dataset():
"""
参数:
无
返回:
X_train, y_train, X_test, y_test -- 训练集特征、训练集目标、测试集特征、测试集目标
"""
### 代码开始 ### (≈ 6 行代码)
train_data = data[:int(len(data)*0.7)]
test_data = data[int(len(data)*0.7):]
X_train = train_data[['btc_total_bitcoins', 'btc_transaction_fees']]
y_train = train_data[['btc_market_price']]
X_test = test_data[['btc_total_bitcoins', 'btc_transaction_fees']]
y_test = test_data[['btc_market_price']]
### 代码结束 ###
return X_train, y_train, X_test, y_test
运行测试
len(split_dataset()[0]), len(split_dataset()[1]), len(split_dataset()[2]), len(split_dataset()[
3]), split_dataset()[0].shape, split_dataset()[1].shape, split_dataset()[2].shape, split_dataset()[3].shape
期望输出
(2043,
2043,
877,
877,
(2043,
2),
(2043,
1),
(877,
2),
(877,
1))
5.4. 3 次多项式回归预测挑战#
划分完训练数据和测试数据之后,就可以构建多项式回归预测模型。挑战要求使用 scikit-learn 完成。
# 加载必要模块
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error
# 加载数据
X_train = split_dataset()[0]
y_train = split_dataset()[1]
X_test = split_dataset()[2]
y_test = split_dataset()[3]
Exercise 5.5
挑战:构建 3 次多项式回归预测模型。
规定:使用 scikit-learn 构建 3 次多项式回归预测模型,并计算预测结果的 MAE 评价指标,同时作为 poly3() 函数返回值。
def poly3():
"""
参数:
无
返回:
mae -- 预测结果的 MAE 评价指标
"""
### 代码开始 ### (≈ 7 行代码)
### 代码结束 ###
return mae
参考答案 Exercise 5.5
def poly3():
"""
参数:
无
返回:
mae -- 预测结果的 MAE 评价指标
"""
### 代码开始 ### (≈ 7 行代码)
poly_features = PolynomialFeatures(degree=3, include_bias=False)
poly_X_train = poly_features.fit_transform(X_train)
poly_X_test = poly_features.transform(X_test)
model = LinearRegression()
model.fit(poly_X_train, y_train)
pre_y = model.predict(poly_X_test)
mae = mean_absolute_error(y_test, pre_y.flatten())
### 代码结束 ###
return mae
运行测试
poly3()
期望输出
1955.8027790596564
5.5. N 次多项式回归预测绘图#
接下来,针对不同的多项式次数,计算相应的 MSE 评价指标数值并绘图。
Exercise 5.6
挑战:计算 1,2,…,10 次多项式回归预测结果的 MSE 评价指标。
规定:使用 scikit-learn 构建 N
次多项式回归预测模型,并计算 1-10 次多项式预测结果的 MSE
评价指标,同时作为函数
poly_plot(N)
的返回值。
from sklearn.pipeline import make_pipeline
from sklearn.metrics import mean_squared_error
def poly_plot(N):
"""
参数:
N -- 标量, 多项式次数
返回:
mse -- N 次多项式预测结果的 MSE 评价指标列表
"""
m = 1
mse = []
### 代码开始 ### (≈ 6 行代码)
### 代码结束 ###
return mse
参考答案 Exercise 5.6
from sklearn.pipeline import make_pipeline
from sklearn.metrics import mean_squared_error
def poly_plot(N):
"""
参数:
N -- 标量, 多项式次数
返回:
mse -- N 次多项式预测结果的 MSE 评价指标列表
"""
m = 1
mse = []
### 代码开始 ### (≈ 6 行代码)
while m <= N:
model = make_pipeline(PolynomialFeatures(m, include_bias=False), LinearRegression())
model.fit(X_train, y_train)
pre_y = model.predict(X_test)
mse.append(mean_squared_error(y_test, pre_y.flatten()))
m = m + 1
### 代码结束 ###
return mse
运行测试
poly_plot(10)[:10:3]
期望输出(结果可能会稍有出入)
[24171680.63629423,
23772159.453013,
919854753.0234015,
3708858661.222856]
Exercise 5.7
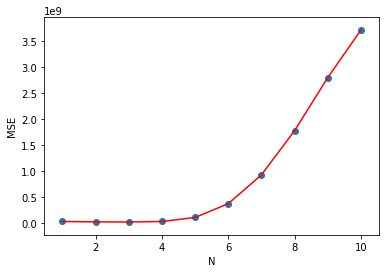
挑战:将 MSE 评价指标绘制成线型图
规定:将
poly_plot(10)
返回的 MSE
列表绘制成组合图(线形图+散点图)。其中,线型图为红色。
mse = poly_plot(10)
## 代码开始 ### (≈ 2 行代码)
## 代码结束 ###
plt.title("MSE")
plt.xlabel("N")
plt.ylabel("MSE")
参考答案 Exercise 5.7
mse = poly_plot(10)
### 代码开始 ### (≈ 2 行代码)
plt.plot([i for i in range(1, 11)], mse, 'r')
plt.scatter([i for i in range(1, 11)], mse)
### 代码结束 ###
### 解法二 ###
plt.plot(mse, marker='-o')
plt.title("MSE")
plt.xlabel("N")
plt.ylabel("MSE")
期望输出
○ 欢迎分享本文链接到你的社交账号、博客、论坛等。更多的外链会增加搜索引擎对本站收录的权重,从而让更多人看到这些内容。